For example, we could mention two tools: Apacha Cassandra and Apache Hadoop ( both were working with distributed systems long before Kuberentes appeared). Hadoop, if I'm not mistaken, from 2000 and Cassandra from 2008....
🚀 Skyrocketing! 🚀 (200+ new stars) 📦 HariSekhonDevOps-Bash-tools ⭐ 4,387 (+296) 🗒 Shell 1000+ DevOps Bash Scripts - AWS, GCP, Kubernetes, Docker, CI/CD, APIs, SQL, PostgreSQL, MySQL, Hive, Impala, Kafka, Hadoop, Jenkins, GitHub, GitLab, BitBucket, Azure DevOps, TeamCity, Spotify, ...
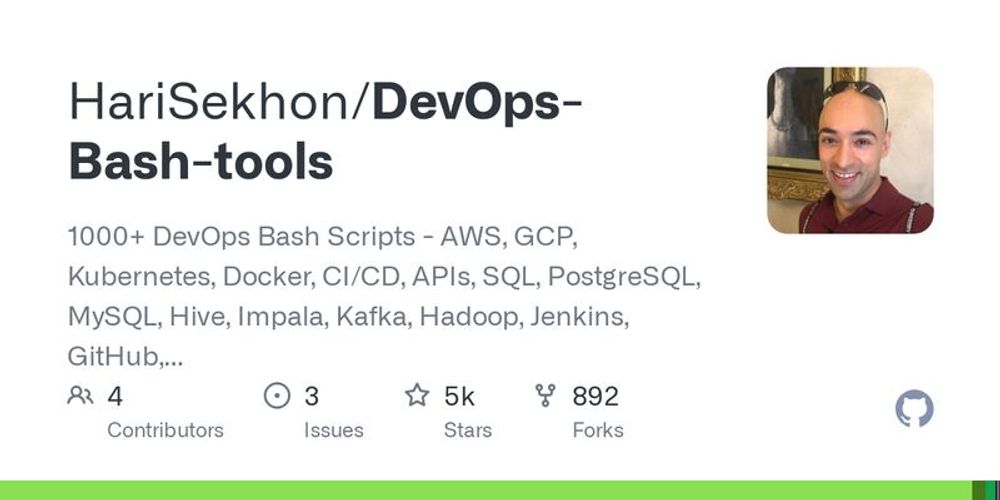
1000+ DevOps Bash Scripts - AWS, GCP, Kubernetes, Docker, CI/CD, APIs, SQL, PostgreSQL, MySQL, Hive, Impala, Kafka, Hadoop, Jenkins, GitHub, GitLab, BitBucket, Azure DevOps, TeamCity, Spotify, MP3,...
Big Analytics Hadoop Market www.openpr.com/news/3656519...

Market Overview The big analytics Hadoop market has grown exponentially in recent years driven by the increasing demand for data processing and analytics solutions With the explosion of data generated...
Hadoop Yarn + Spark. To apanhando pra cacete pra fazer um docker rodar pelo Yarn com o classpath que preciso
❀ Big Data: Conjunto de dados extremamente grandes e complexos que requerem tecnologias avançadas para processamento e análise. Ex: Usar Hadoop para processar grandes volumes de dados de redes sociais.
📦 HariSekhonDevOps-Bash-tools ⭐ 2,909 (+22) 🗒 Shell 1000+ DevOps Bash Scripts - AWS, GCP, Kubernetes, Docker, CI/CD, APIs, SQL, PostgreSQL, MySQL, Hive, Impala, Kafka, Hadoop, Jenkins, GitHub, GitLab, BitBucket, Azure DevOps, TeamCity, Spotify, MP3, LDAP, Code/Build Linting, pkg mgmt...
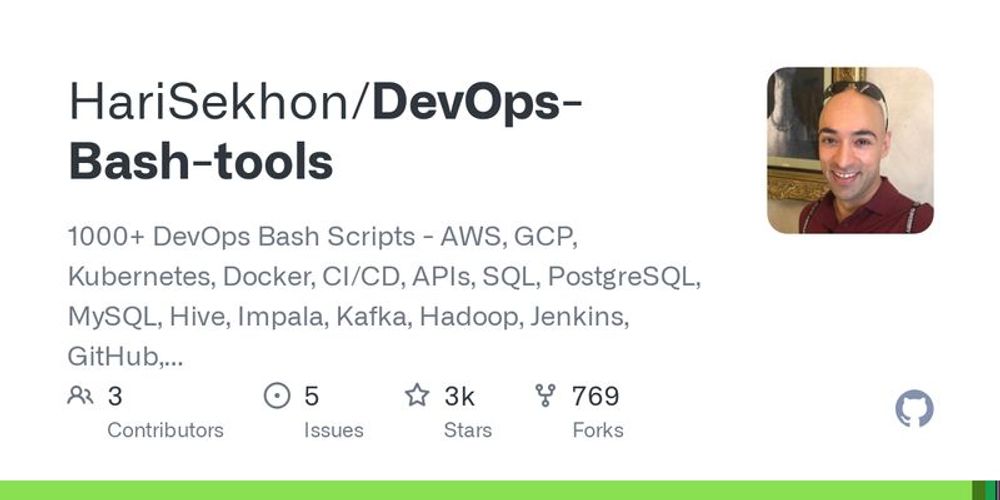
1000+ DevOps Bash Scripts - AWS, GCP, Kubernetes, Docker, CI/CD, APIs, SQL, PostgreSQL, MySQL, Hive, Impala, Kafka, Hadoop, Jenkins, GitHub, GitLab, BitBucket, Azure DevOps, TeamCity, Spotify, MP3,...
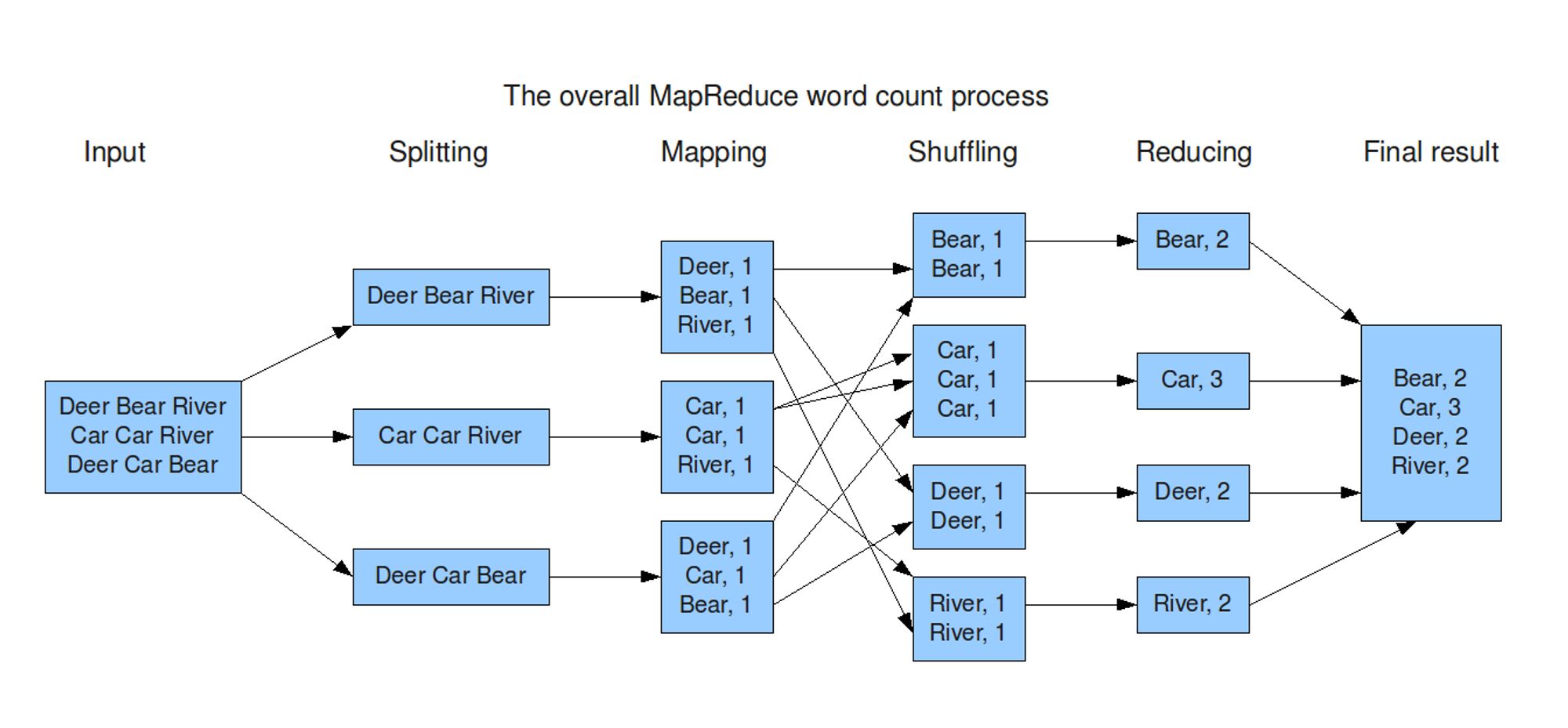
O termo embaralhamento no MapReduce não faz muito sentido pra mim. Embaralhamento é misturar, tirar da ordem. No MapReduce é o contrário, é o momento em que você junta os pares de chaves iguais. 🤷🏻♂️
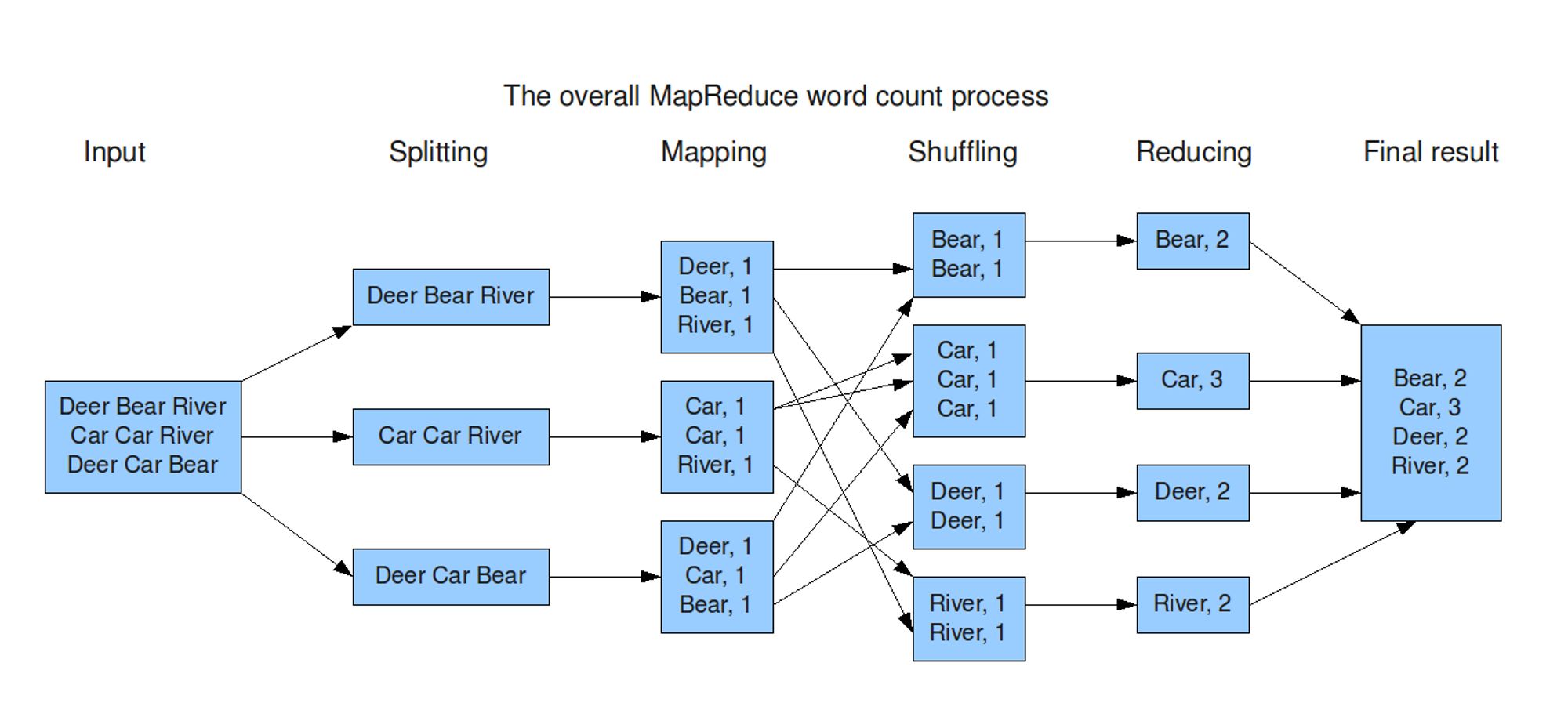
O termo embaralhamento no MapReduce não faz muito sentido pra mim. Embaralhamento é misturar, tirar da ordem. No MapReduce é o contrário, é o momento em que você junta os pares de chaves iguais. 🤷🏻♂️
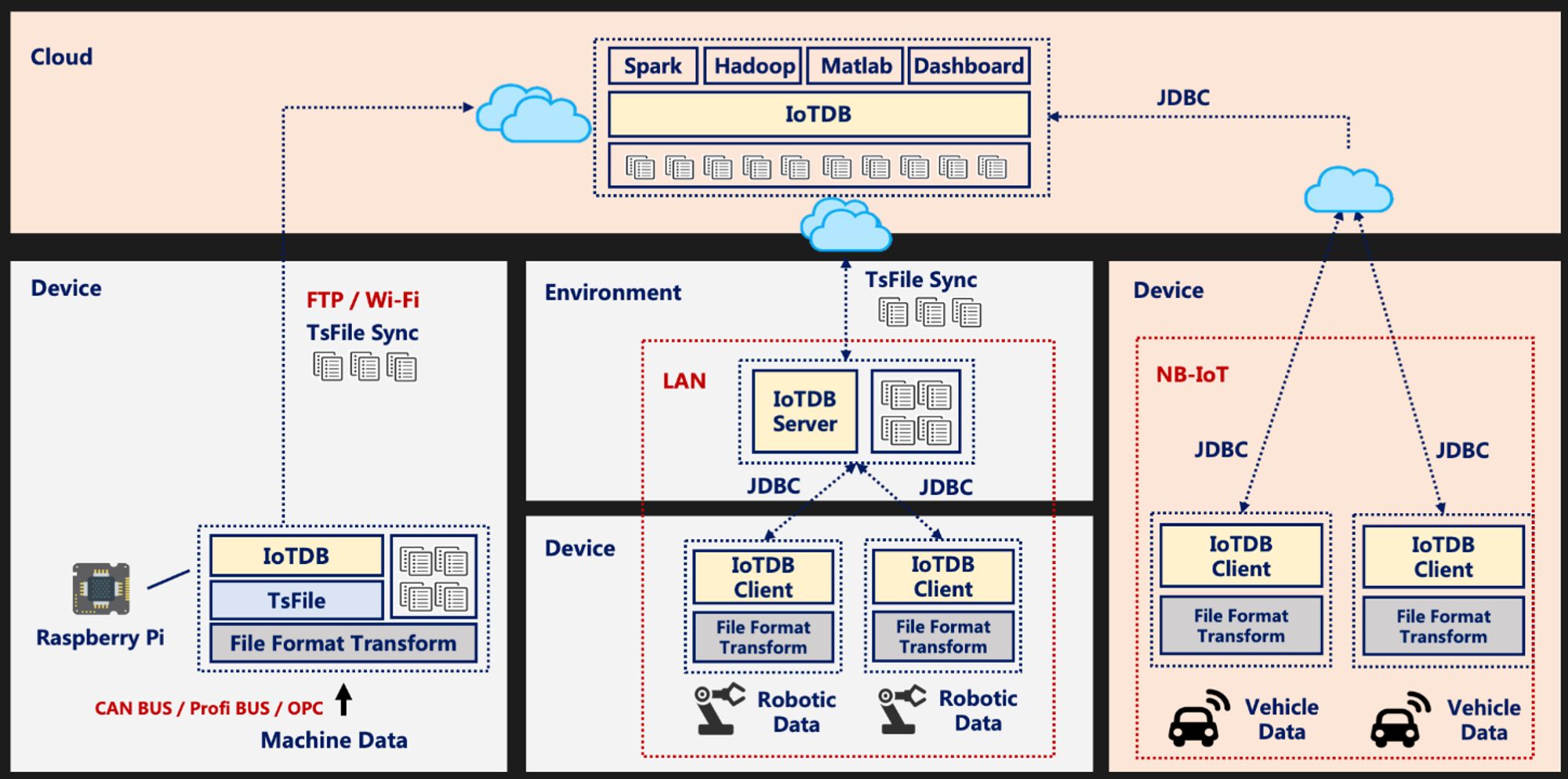
Apache IoTDB : une base de données spécialement conçue pour les time series avec une intégration fluide dans les écosystèmes Hadoop et Spark. 👉 En savoir plus : iotdb.apache.org/github.com/apache/iotdb
How Uber laid the foundations for the batch data cloud migration by incorporating key data mesh principles www.uber.com/blog/datamesh/#datamesh#dataengineering#hadoop

Learn how Uber is streamlining the Cloud migration of its massive Data Lake by incorporating key Data Mesh principles.