
Read the ICML 2024 best paper on stealing model weights. Really smart approach of using SVDs to steal the LLM's hidden dimension count and last layer weight matrices! ICML: icml.cc/virtual/2024...arxiv.org/abs/2403.06634

Come discuss an ICML best paper award with the author Rob Brekelmans in our reading group on Monday! "Probabilistic Inference in LMs via Twisted SMC" arxiv.org/abs/2404.17546portal.valencelabs.com/logg

This might be "simply" because peer review is structurally broken (or I've outdated views! I haven't done this in years), but my perspective from reviewers in vis, eurovis, icml, neurips, kdd and facct was "they work with the venue's best interests at heart, not mine"
Reminds me of two papers that caught my eye at ICML. 🧵 1/ In the Platonic Representation Hypothesis, the authors postulate that neural networks trained with different objectives and architectures on different data and modalities converge to the same statistical model in representation space.
I posted my blog about Genie🧙 skyfoliage.com/pubstore/cm0...medium.com/@taks.skyfol...#magic#genie#vision#game#creator#environment#transformer#VisionTransformer#ICML#google#DeepMind#skyfoliage.com
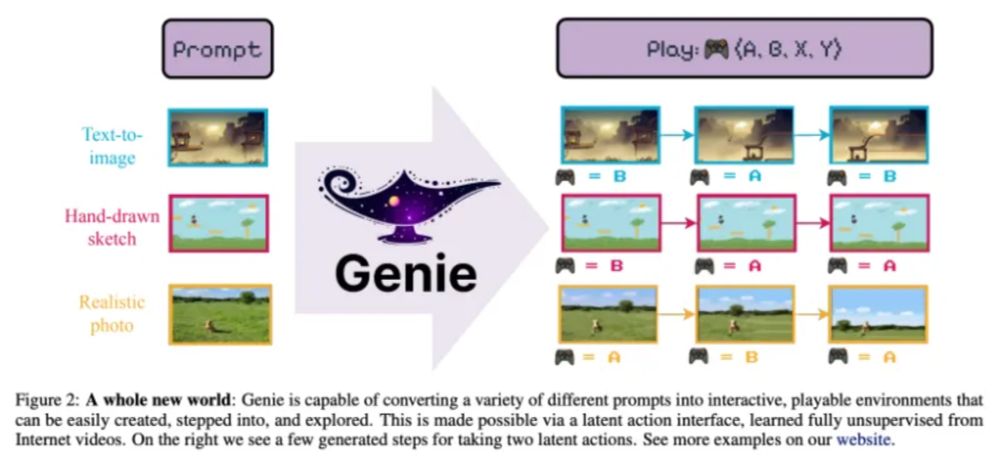
This article describe about a paper of Genie in ICML 2024.
The conference rotation seems reasonably sustainable to me? If the reviewing system doesn't entirely collapse, I don't see the cadence of NeurIPS, AAAI, IJCAI, ICML, ICLR, EMNLP etc. going away, with or without social media.
"Learning Decision Trees and Forests with Algorithmic Recourse" presented on ICML 2024 | fltech - 富士通研究所の技術ブログ

Introduction Hi! This is Kentaro Kanamori from Artificial Intelligence Laboratory. We are conducting research and development on "XAI-based Decision-Making Assistant" and trying to apply our technologies to real decision-making tasks (e.g., discovering actions for imprving employees' productivity fr…
ICML'24 in Vienna was great, thanks to all organizers! Here you can enjoy all our workshop submissions in detail: ge.in.tum.de/2024/08/02/i... Among others: Flow matching for inverse problems with physics constraints, higher-order differentiable Navier-Stokes solvers, Equivariance in GNNs ...
