
Honestly, surprised by how chill everyone is when I ask to opt-out of facial recognition which is the default at SLC airport security and gates for at least a year
I left my apartment and finished security in 40 minutes yesterday! No issues with flights either. Flew with delta

🤖 #bskai
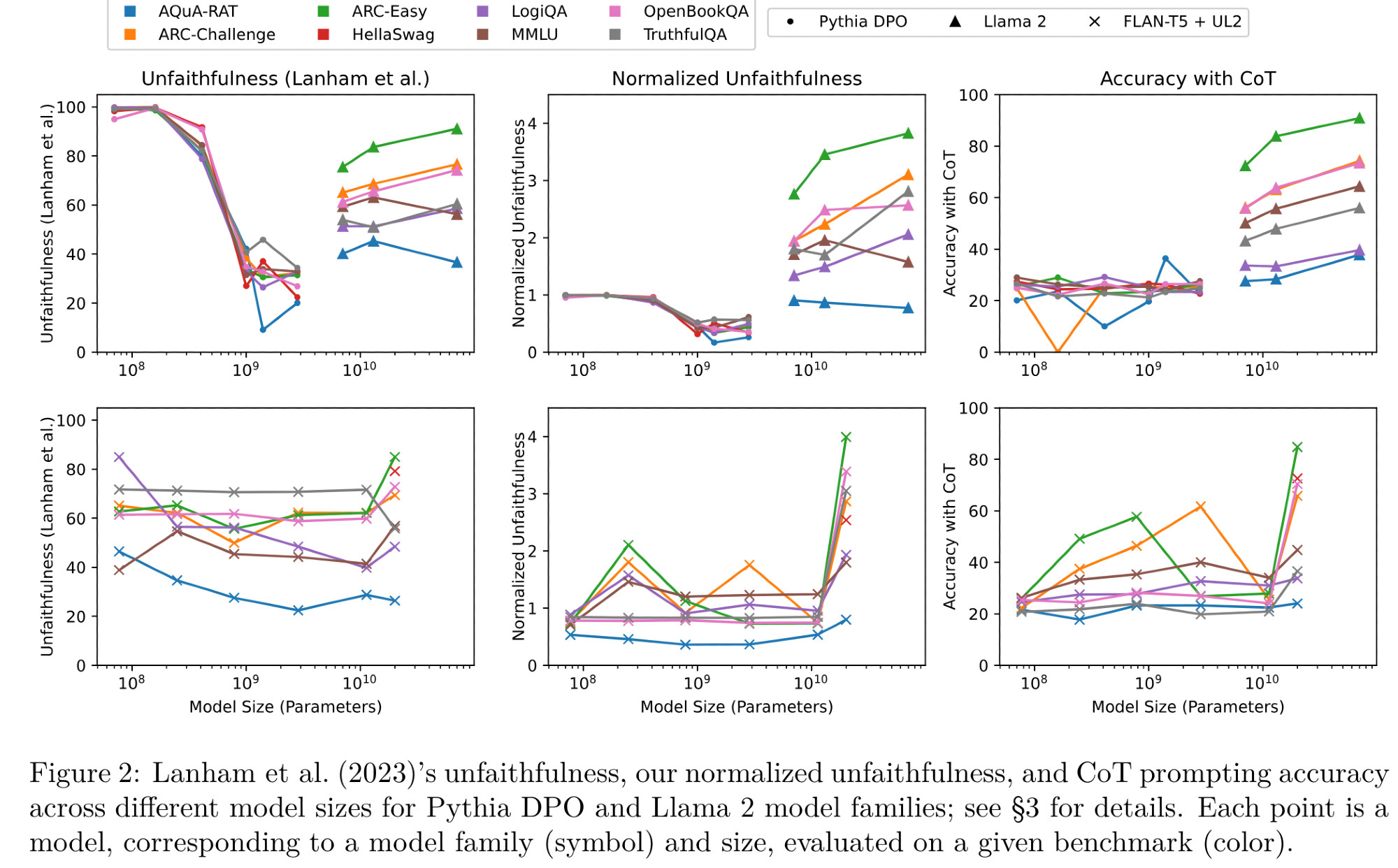
In the TMLR paper arxiv.org/abs/2402.14897, we replicate 📉📈 relationship between model size and the final measure of faithfulness in Lanham et al. (2023; arxiv.org/abs/2307.13702) with open-weights models; yay, but...

Understanding the extent to which Chain-of-Thought (CoT) generations align with a large language model's (LLM) internal computations is critical for deciding whether to trust an LLM's output. As a...
In the TMLR paper arxiv.org/abs/2402.14897arxiv.org/abs/2307.13702) with open-weights models; yay, but...
Understanding the extent to which Chain-of-Thought (CoT) generations align with a large language model's (LLM) internal computations is critical for deciding whether to trust an LLM's output. As a...
In any case, I'm excited about measurements of CoT faithfulness grounded in model internals, instead of those produced by intervening only on inputs/outputs. That's hard, but hey, at least there is more groundbreaking research to be done!!
Is it likely that... ...accuracy is strongly indicative of the intricate concept of CoT faithfulness? ...accurate models produce very unfaithful, but also very plausible CoTs, meaning that they actually reason differently from people in all cases where they solve the task well?
Well, eliminating inverse scaling led us to check the correlation between accuracy and Lanham et al. (2023)'s unfaithfulness, and turns out these two are correlated, which we believe is an issue. I'll discuss why next ⬇️
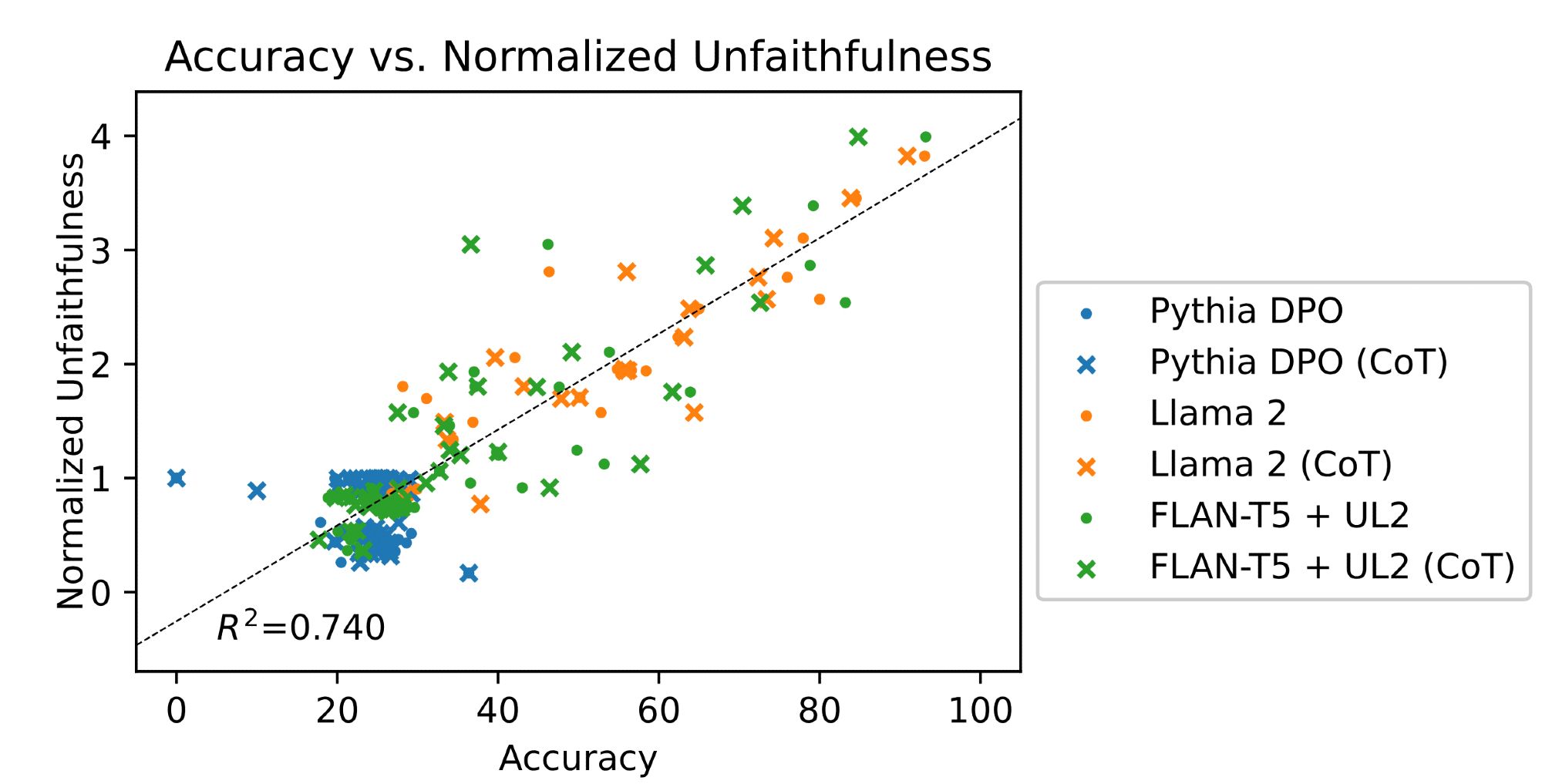
...after accounting for a model's bias toward certain answer choices, we show that Lanham et al. (2023)'s unfaithfulness drops significantly for smaller less-capable models; so what?
In the TMLR paper arxiv.org/abs/2402.14897arxiv.org/abs/2307.13702) with open-weights models; yay, but...
Understanding the extent to which Chain-of-Thought (CoT) generations align with a large language model's (LLM) internal computations is critical for deciding whether to trust an LLM's output. As a...