
I know little about evolutionary biology. But scientists 🧪 must stop thinking of writing as meriting just the minimal effort to get into the best journal possible, and rather as *the* point of their work. Results and venue mean nothing unless people can understand and be convinced by the story
The call for papers for the 2024 NICE Conference is now up! easychair.org/cfp/NICE2024 We will be in San Diego next year - on the beach in La Jolla! - in late April. Come join us!
I can barely write without a bit of snark or speculation (or both, depending on my mood). I don't see what the point is otherwise - if writing is boring, no one is ever going to read or remember it. More people should view writing as an opportunity to win minds; not a painful step towards a CV entry
This paper is itself kind of a sample of how to do synaptic sampling. In some ways it is kind of the simplest thing we can do with Bernoulli sampling of weights in a neural network. But it shows that there may be great opportunities if we break free of the mindset of doing what is easy on GPUs 10/10
5) Finally, we can skew training data to have underrepresented training classes, and we see that indeed entropies around those classes increase. 9/
4) We can quantify the entropy of a network’s output distributions, and we see that high entropy outputs are more likely to be misclassified than low entropy. In effect, accuracy correlates with confidence! 8/
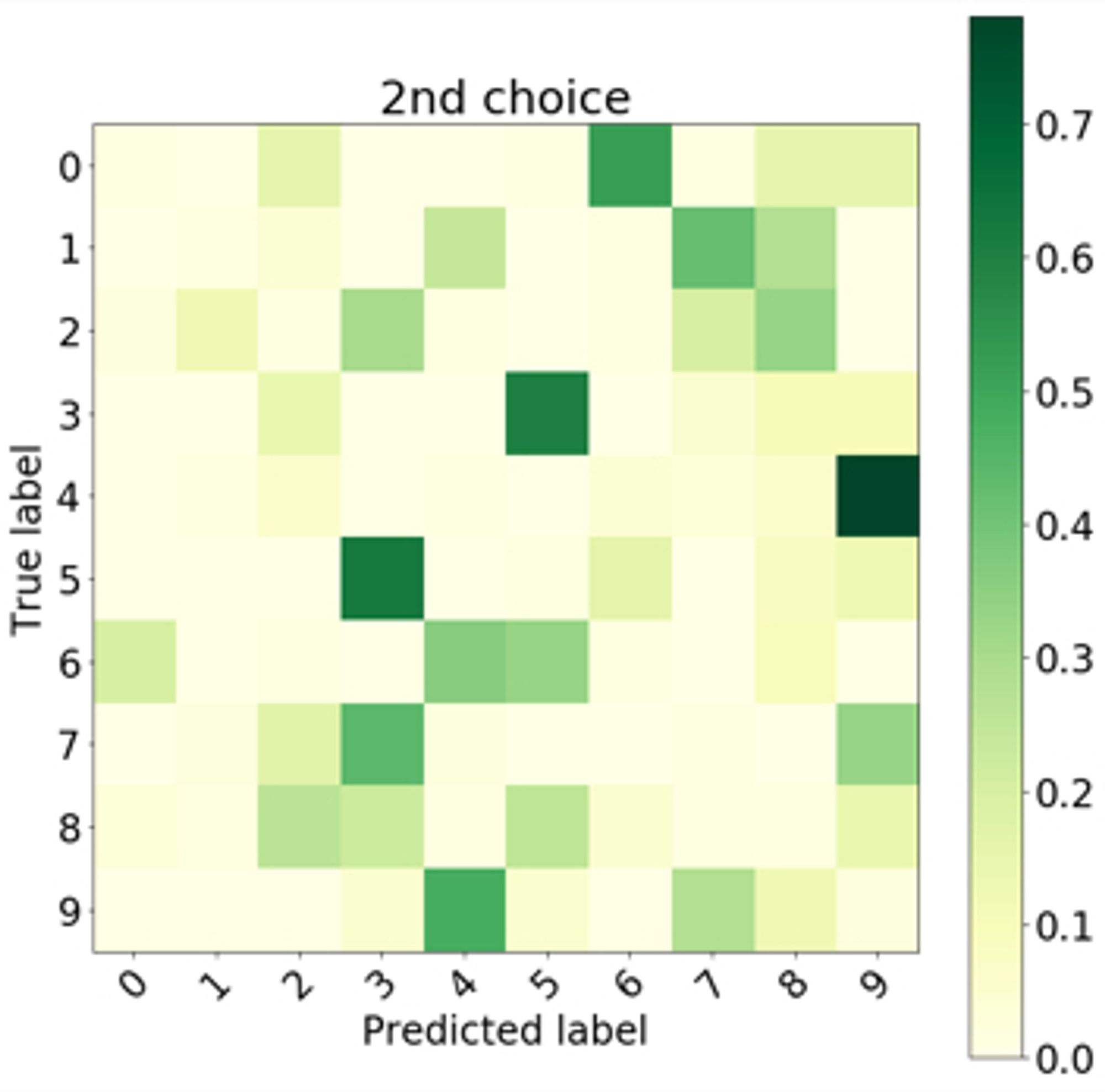
2) More interestingly, the 2nd most popular choice reflects uncertainty you would naively expect. Shirts and jackets on Fashion MNIST; dogs and deer on CIFAR-10. 1’s and 7’s on MNIST. 3) This amazingly seems pretty robust to precision in the probabilities. 7/
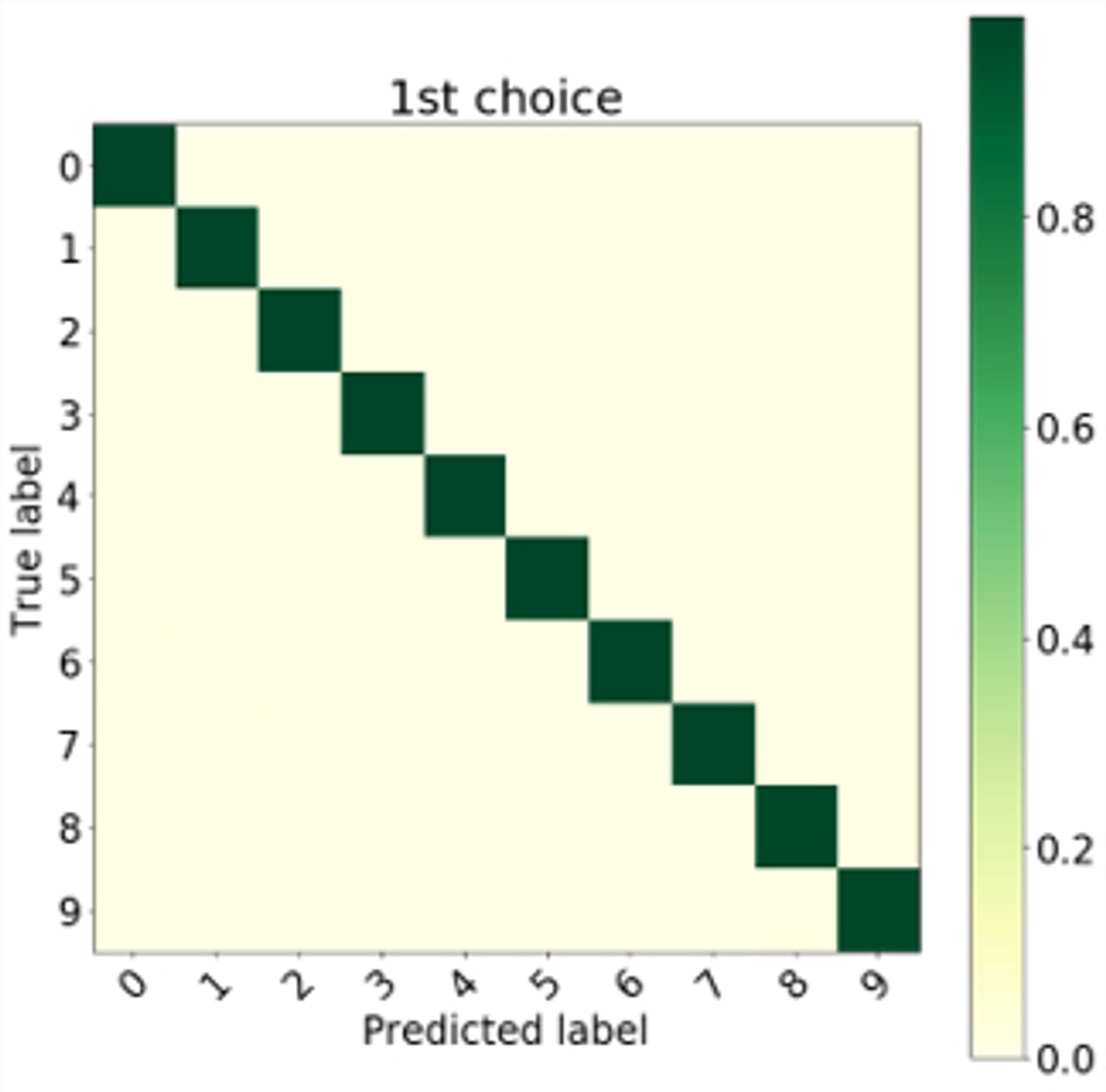
The paper – which is pretty short – goes into all of the details. But punchlines: 1) it works. With minimal impact on training, majority vote of samples gets pretty close to deterministic accuracy in classification. 6/
Well, for a single run of the network, that random binarized network is really noisy and any single output is pretty likely to be wrong. But if you do this many times, those samples create a distribution which… amazingly… looks like a distribution you would want from a classifier! 5/
So a naïve proposition; what if I view my ANN weights as a probability of being a 1 or 0; not as a conductance? For each weight, I just stick my weighted coin in there, and I get a nice efficient binary weight matrix that I can run many times to collect a lot of independent samples. 4/