
Human feedback is critical for aligning LLMs, so why don’t we collect it in the open ecosystem?🧐 We (15 orgs) gathered the key issues and next steps. Envisioning a community-driven feedback platform, like Wikipedia alphaxiv.org/abs/2408.16961 🧵🤖

I was involved in the "more or less", e.g. to avoid reconstruction through a canonical basis as inputs you can use invariances such as sending a permuted network each time
And apparently you can multiply (super fast) by encoding the matrix as a light wave, then the multiplication is the two waves meeting and the output is more or less the only thing you can do.
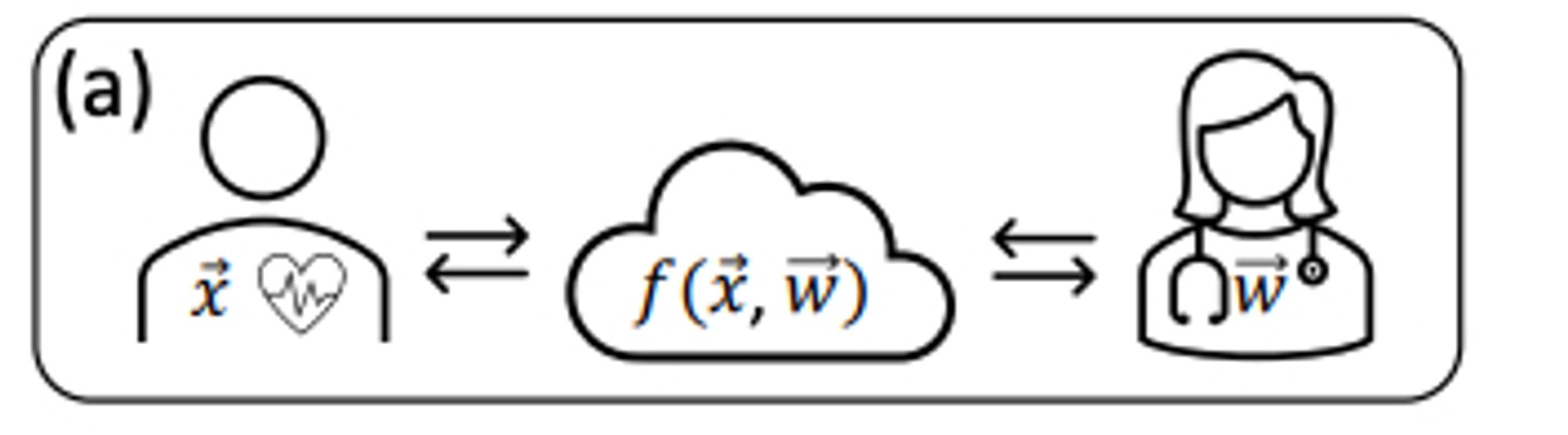
The basic Idea is that for every multiplication in the network you multiply two symmetric things an input and an output matrix. So, if each side can send a matrix but only read the output each can keep their secret (one the input one the model weights) www.alphaxiv.org/abs/2408.05629

Comment directly on top of arXiv papers.
Ask your friends directly, it might have been a mistake or have reasoning. (or ask us, we probably know better :P )

Basically, like we evaluate everything else. Measure one thing at a time (don't also test a new model) Have a specific claim (is it language diverse, background,origin) and quantify it Separate it from other constructs like how much data was collected or whether it is biased
