
It's not a lower bound because if you are willing to do enough compute you can do better than SGD for training models its inefficient but possible. The paper claims it is very similar to Newton's method (based on 2nd order so gradient of gradient)
So, why do we care? Because we don't know any algorithm that computes only the gradient and converges that fast Transformers learn with their layers an algorithm that is better The paper has more theoretical and other measures to compare it to the newton's but the gist is up IMO
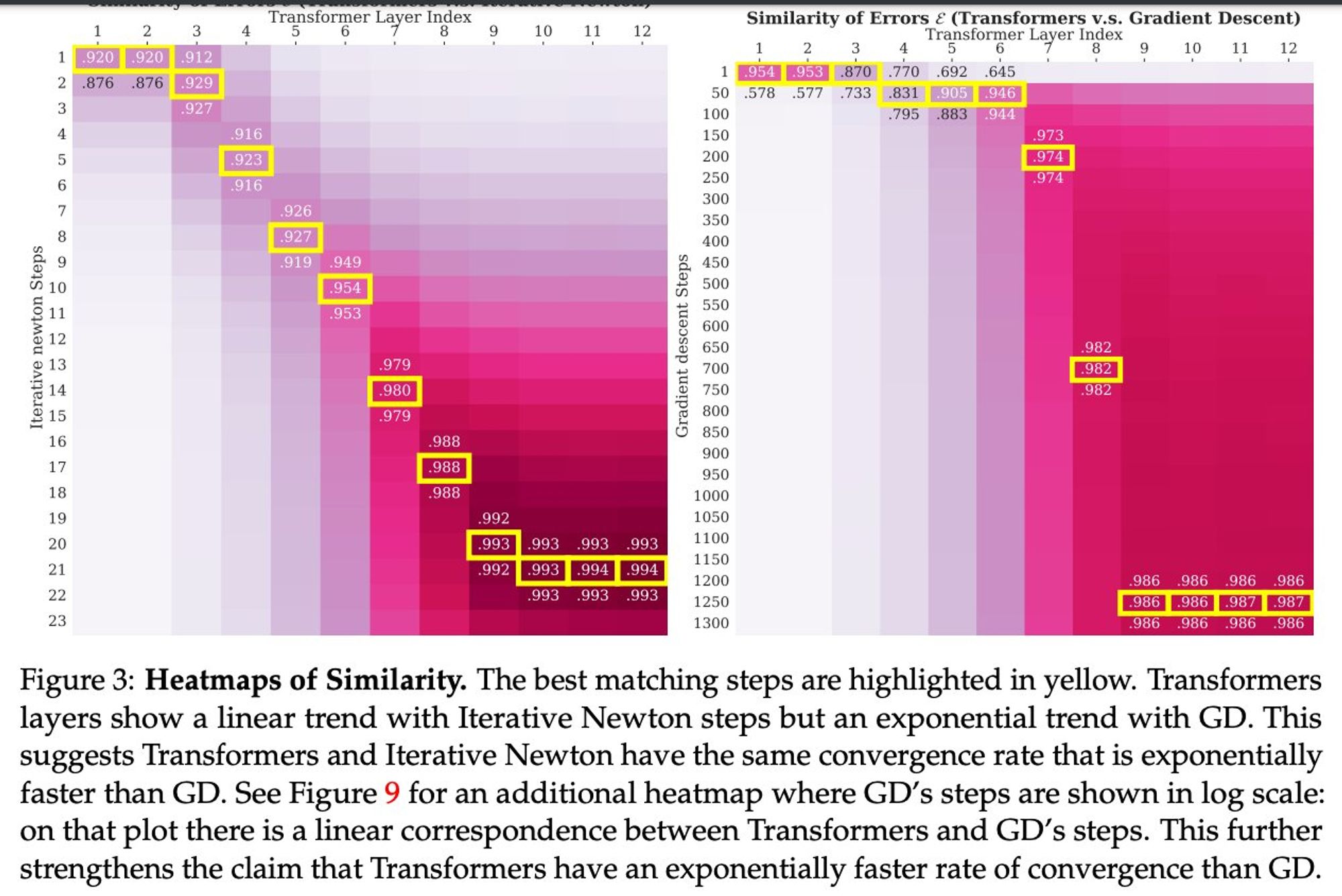
What they see is that if you take every layer to be comparable to steps of an algorithm, the layers succeed much faster than SGD, note that they are even curved down, not up like SGD (Super linearity to the rescue🦸♀️)
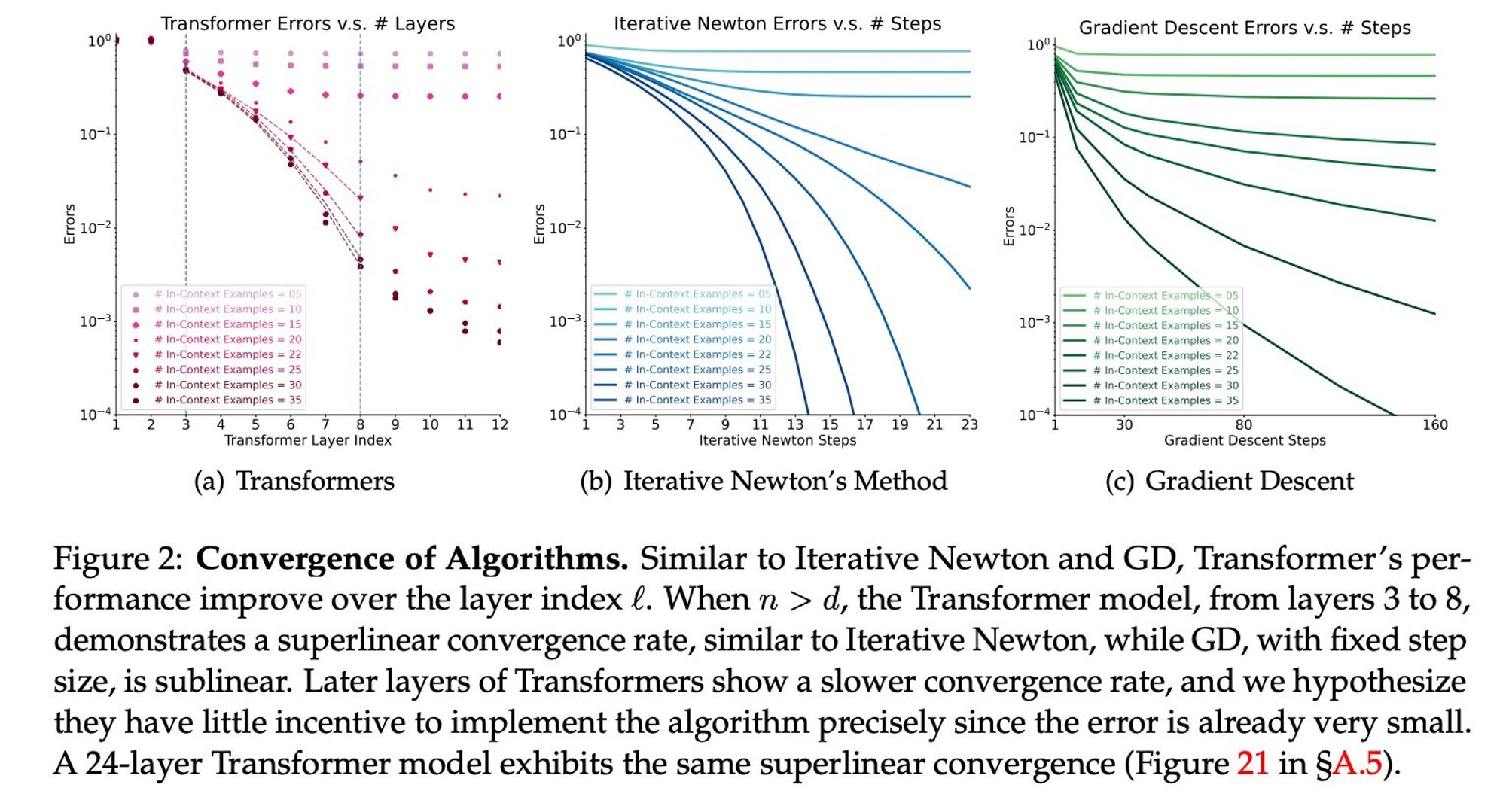
What they see is that if you take every layer to be comparable to steps of an algorithm, the layers succeed much faster than SGD, note that they are even curved down, not up like SGD (Super linearity to the rescue🦸♀️)
So how do you compare transformers to classic algorithms? You train them to do ICL on simple closed problems we understand and know how to solve in other ways (e.g. SGD or second-order derivatives like Newton's iterative) For example, compute a linear function from examples seen

In alphaxiv.org/pdf/2310.17086 they discuss what is internally learnt when you give a model examples and it manages to understand how to act upon it. also known as ICL

Comment directly on top of arXiv papers.
It was claimed in-context-learning (ICL) is doing SGD inside the transformer layers. A new finding shows this is not possible. They must be doing something BETTER In fact, exponentially better than SGD, so second-order methods?🧵 🤖
Comment directly on top of arXiv papers.
I wish, in these days there are many days I don't get to read it, especially busy times.
We are all used by now to delve into topics full of LLM influence. But, did you know we started speaking like that too? In other words, LLMs drive language change, our language, not only the copy-pasted text. alphaxiv.org/abs/2409.13686#LLM#LLMs#ML#machinelearning#nlproc#language#change 🤖
Want to incorporate your benchmark into BenchBench? Make a PR skeptical about the idea of BenchBench? comment! Details? Read: www.alphaxiv.org/abs/2407.13696bsky.app/profile/lcho...

Recent advancements in Language Models (LMs) have catalyzed the creation of multiple benchmarks, designed to assess these models' general capabilities. A crucial task, however, is assessing the...