
LC
Leshem Choshen
@lchoshen.bsky.social
148 followers107 following317 posts
What they see is that if you take every layer to be comparable to steps of an algorithm, the layers succeed much faster than SGD, note that they are even curved down, not up like SGD (Super linearity to the rescue🦸♀️)
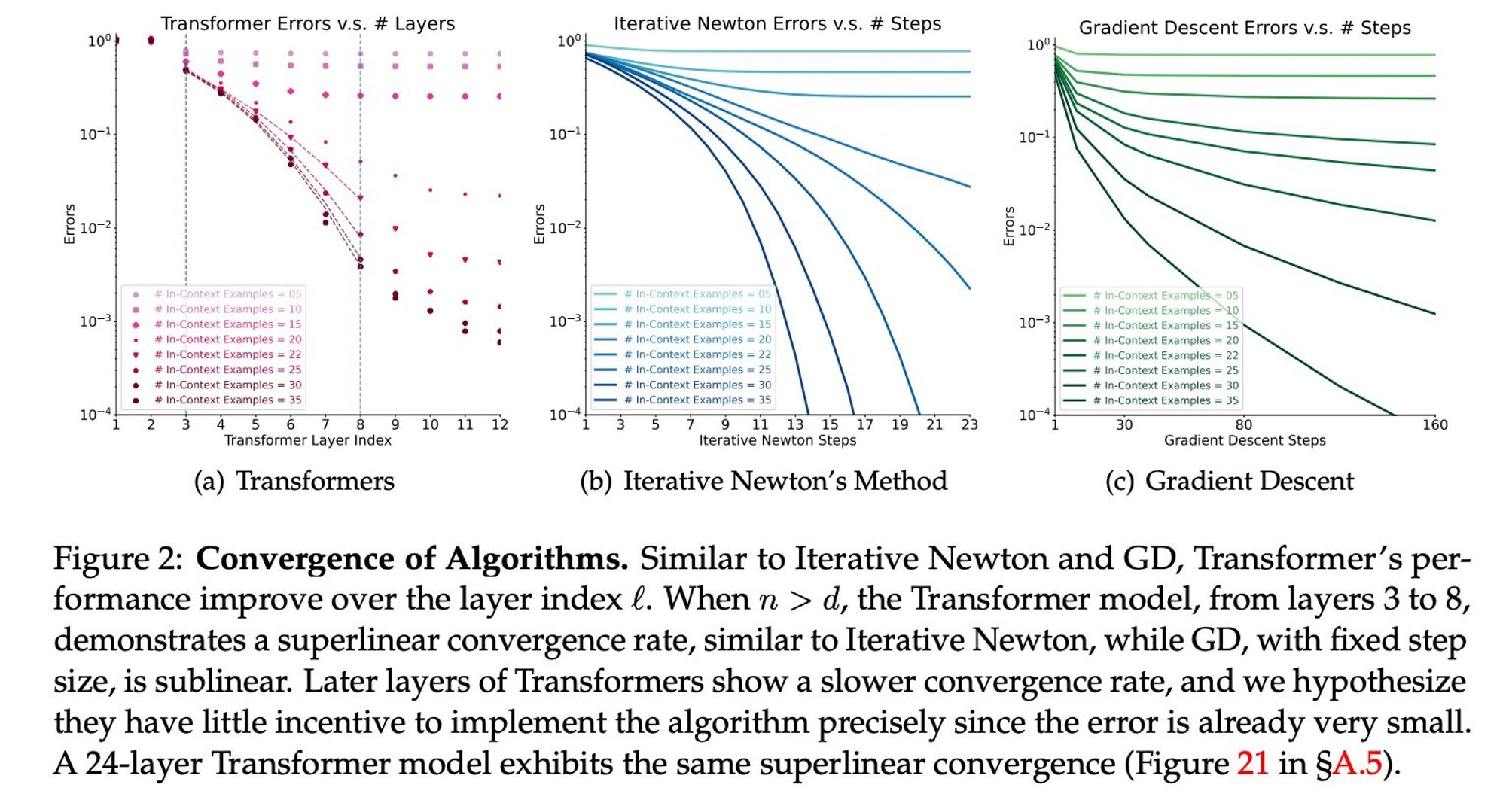
So, why do we care? Because we don't know any algorithm that computes only the gradient and converges that fast Transformers learn with their layers an algorithm that is better The paper has more theoretical and other measures to compare it to the newton's but the gist is up IMO
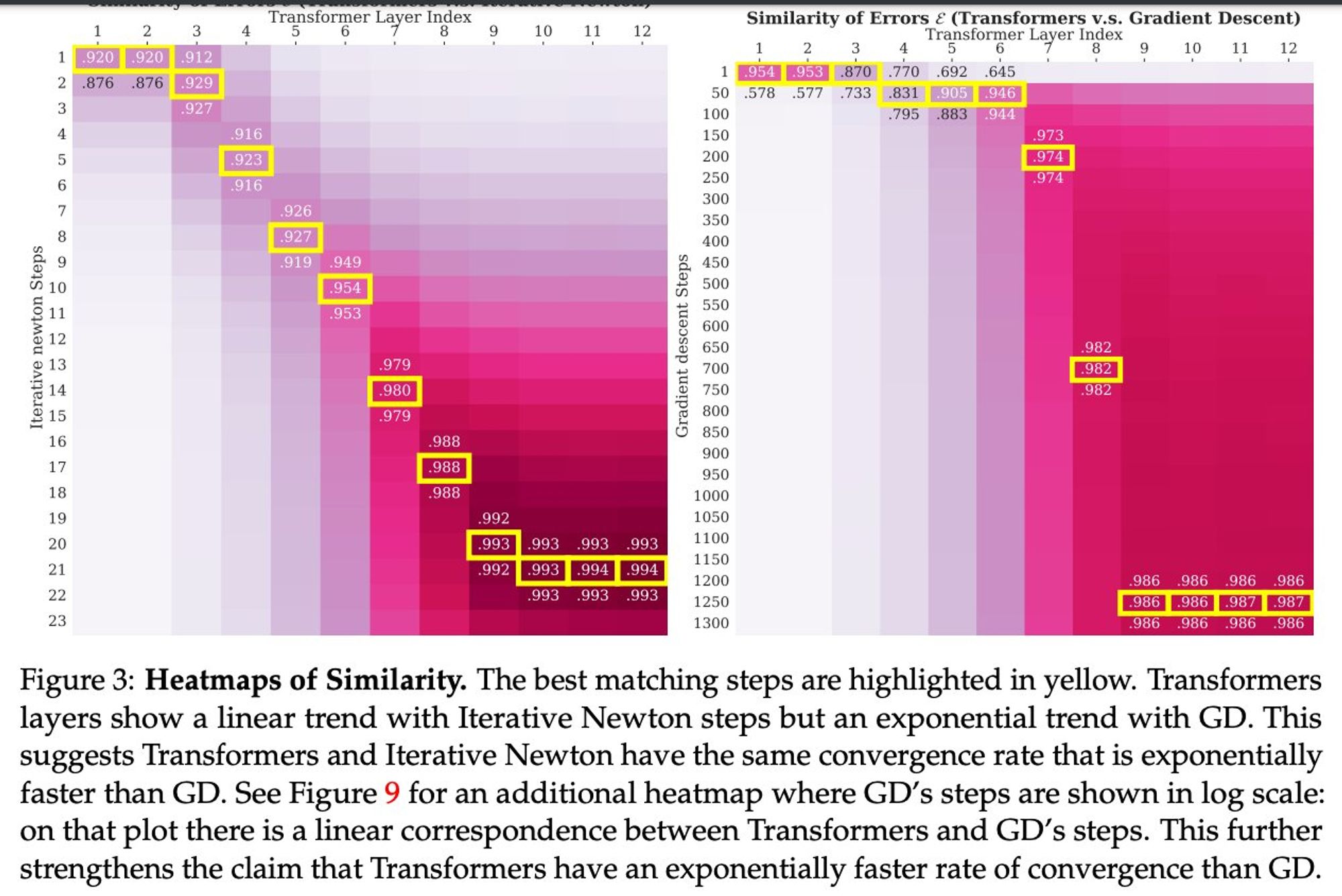
LC
Leshem Choshen
@lchoshen.bsky.social
148 followers107 following317 posts