

Overall, the work shows how LLMs can be adapted to annotate dream reports from different populations with minimal supervision, potentially allowing for standardised and replicable annotation of large datasets for research purposes!
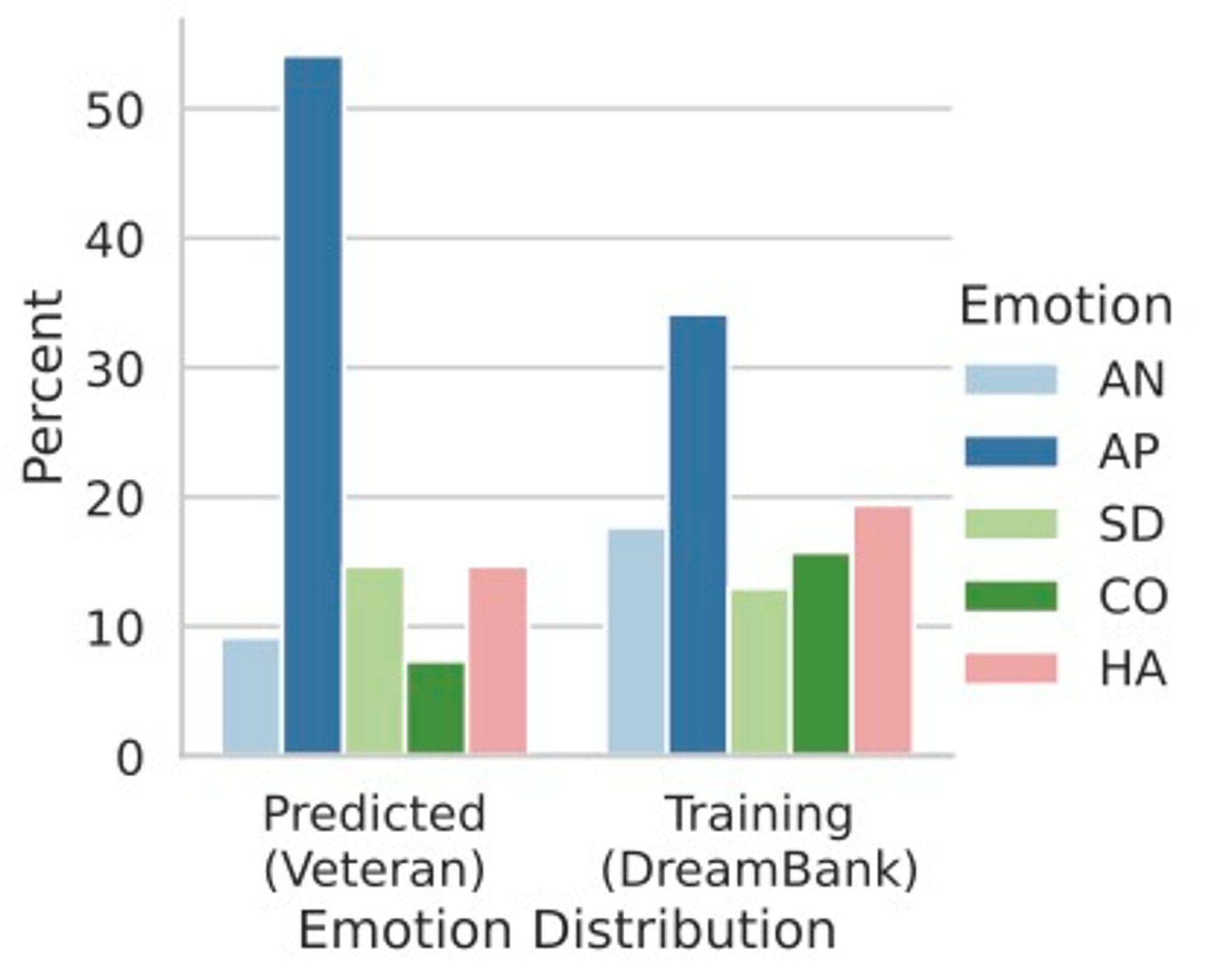
Lastly, we tested if our model was robust to OoD unlabeled data from a subject with a diagnosed PTSD (a Veteran of the Vietnam War), and found that the model’s prediction fit the *expected* emotion distribution, without simply mimicking the training distribution.
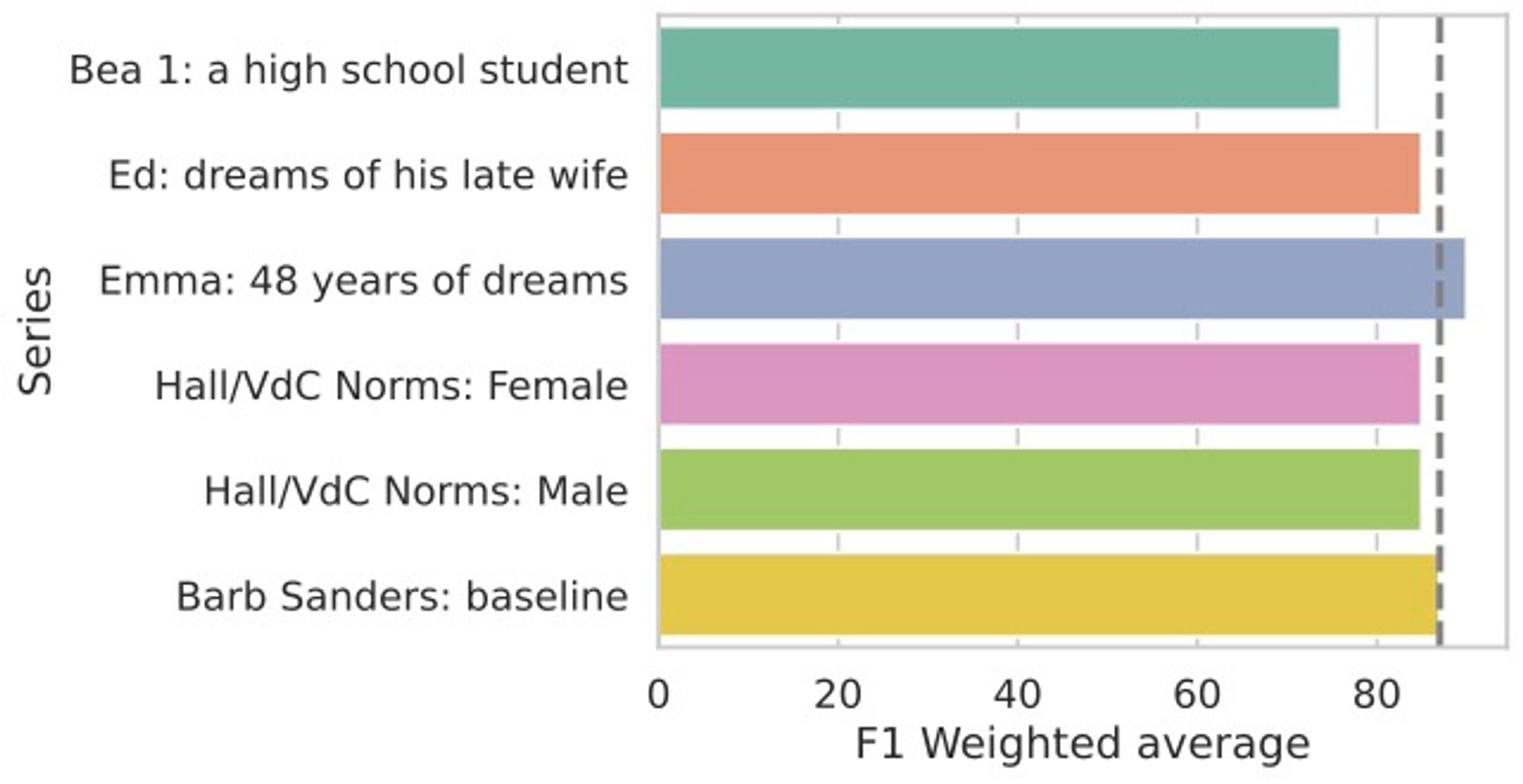
We also conducted an ablation experiment, to understand if the performance was influenced by memorisation or implicit statistics within different series (subsets of DreamBank), but found no significant evidence of these differences impacting the model.

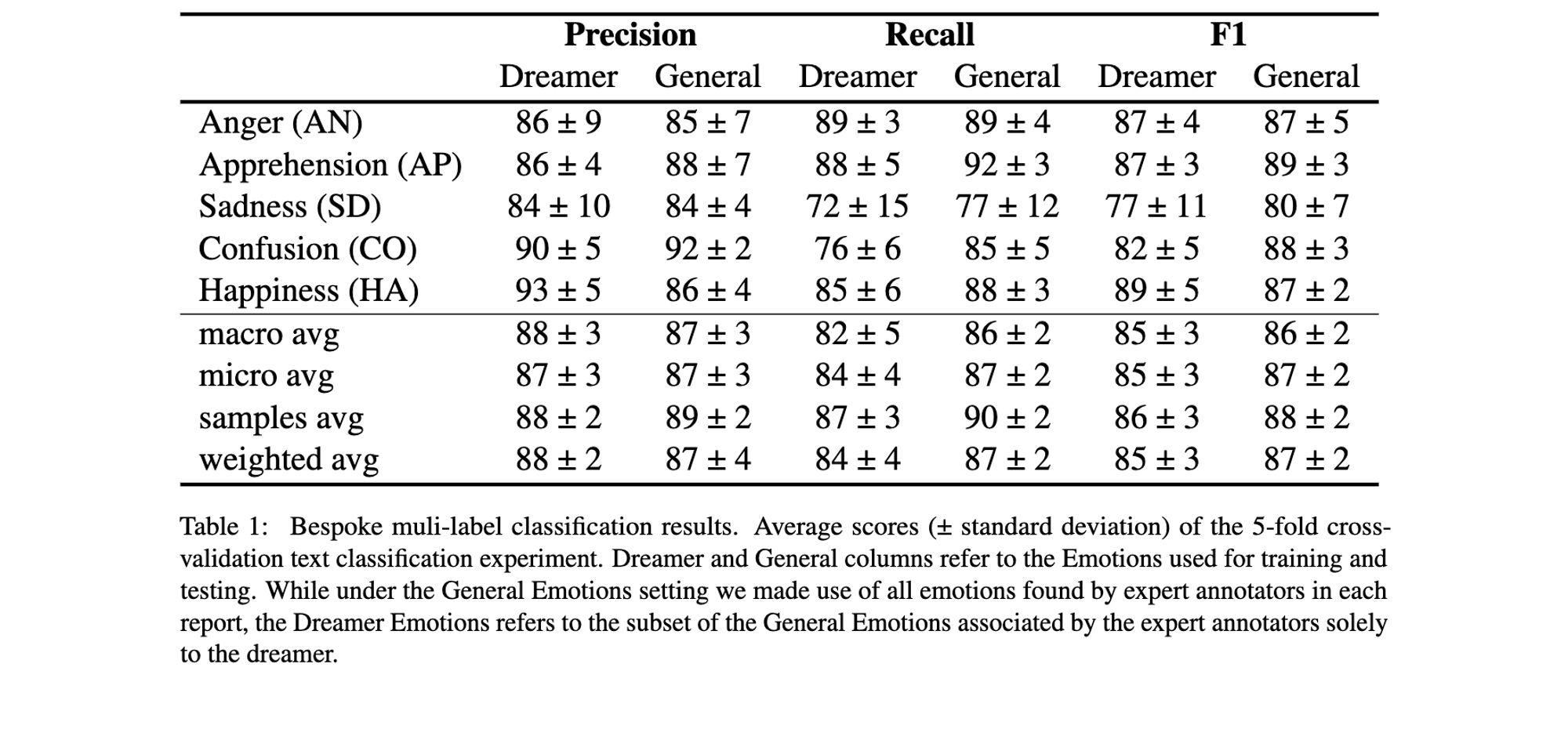
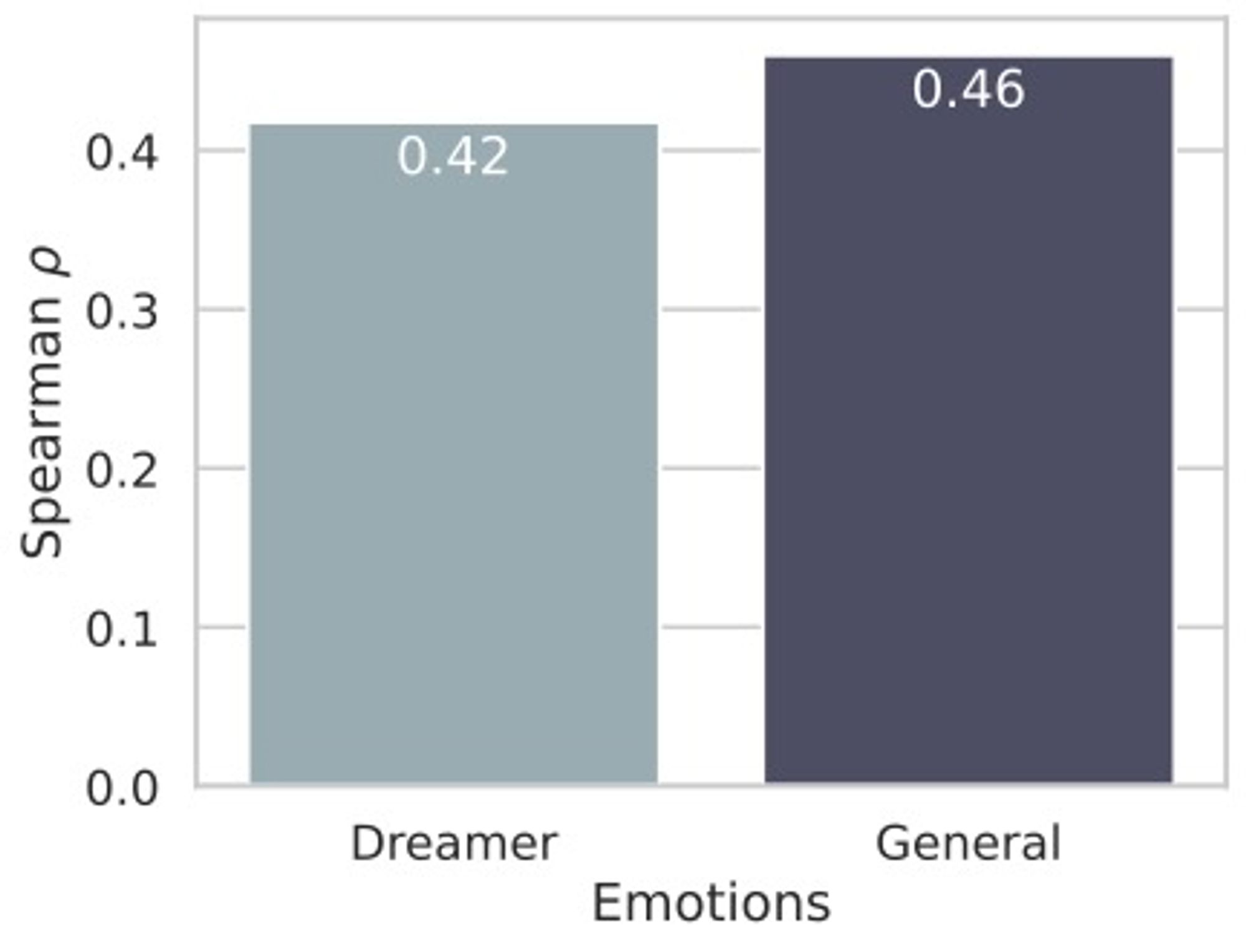
Our main results show a generally strong and stable performance across most single emotions and emotion sets, aside from a widespread poor performance for sadness.
We hence reframed the task to suit the HVDC scoring method. Using a multi-label setting, we trained a model to predict if each of the 5 HVDC emotions was appearing independently!

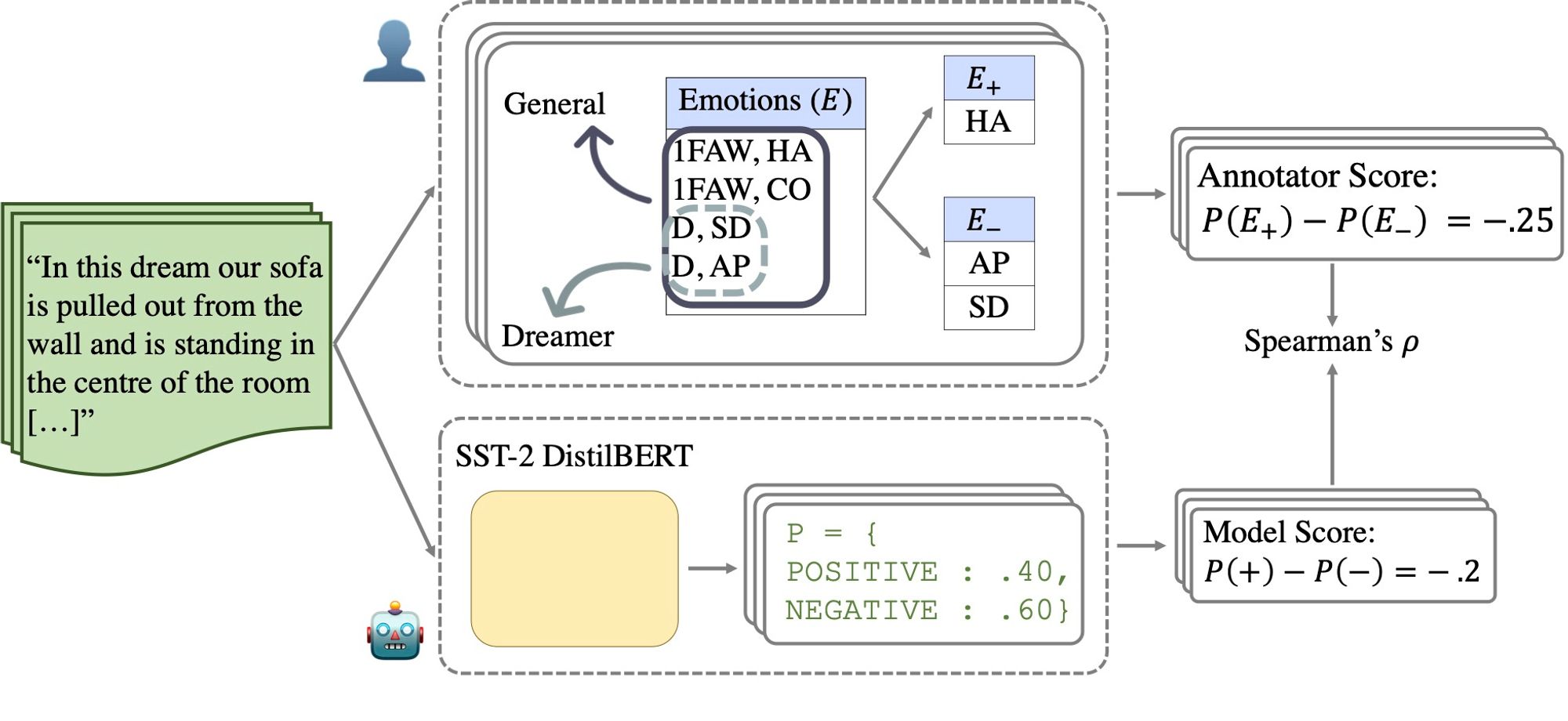
Preliminary experiments showed that binary predictions from an LLM pre-trained on sentiment analysis do not correlate with the general sentiment of a report, nor with single positive/negative emotions.
Longer story: we study if LLMs can be used to replicate HVDC emotion feature, and, if so, with which granularity? Can we do so without supervision? If not, how robust is a supervised classifier to biases and out-of-distribution (OoD) data?
Thanks for reading 😀. The literature around NLP tools to study dream reports goes quite back (see Elce et al 21), but they kinda "got stuck" on word-dictionaries, word2vec and simple NeuralNets. Here we tried to overcome many existing limitations with different types of LLMs!