
TU
Ted Underwood 🦋
@tedunderwood.me
Uses machine learning to study literary imagination, and vice-versa. Likely to share news about AI & computational social science / ciência social computacional / 計算社会科学.
Information Sciences and English, UIUC. Author of Distant Horizons (Chicago, 2019).
4.6k followers2.9k following8.5k posts
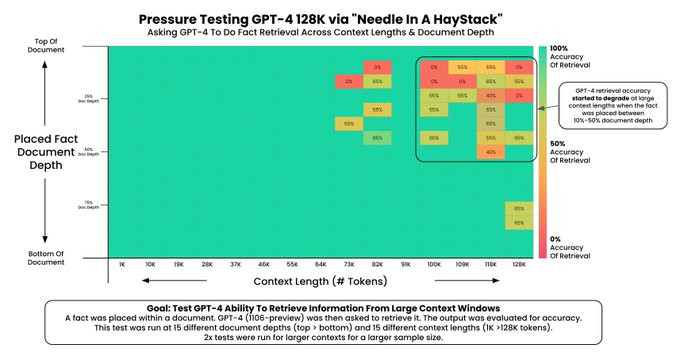
Greg Kamradt spent $200 to test the new 128,000-token context length on GPT-4. Can it remember a fact buried in tens of thousands of words of prose? The answer: yes, up to about 64k tokens. Beyond that, it matters where you placed the fact in the prompt. link to thread: twitter.com/GregKamradt/...
TU
Ted Underwood 🦋
@tedunderwood.me
Uses machine learning to study literary imagination, and vice-versa. Likely to share news about AI & computational social science / ciência social computacional / 計算社会科学.
Information Sciences and English, UIUC. Author of Distant Horizons (Chicago, 2019).
4.6k followers2.9k following8.5k posts