DE
David Epstein
@davidnotdave.bsky.social
Literature major, then neuroscience Ph.D., then addiction researcher. Enough-knowledge-to-endanger-myself in social sciences and statistics. He/him. Views my own.
110 followers118 following20 posts
I kinda startled myself with this little experiment in power calculations. You can have zero ability to find the effect you're looking for, but more than zero "power," all of which reflects your likelihood of overestimating the effect.
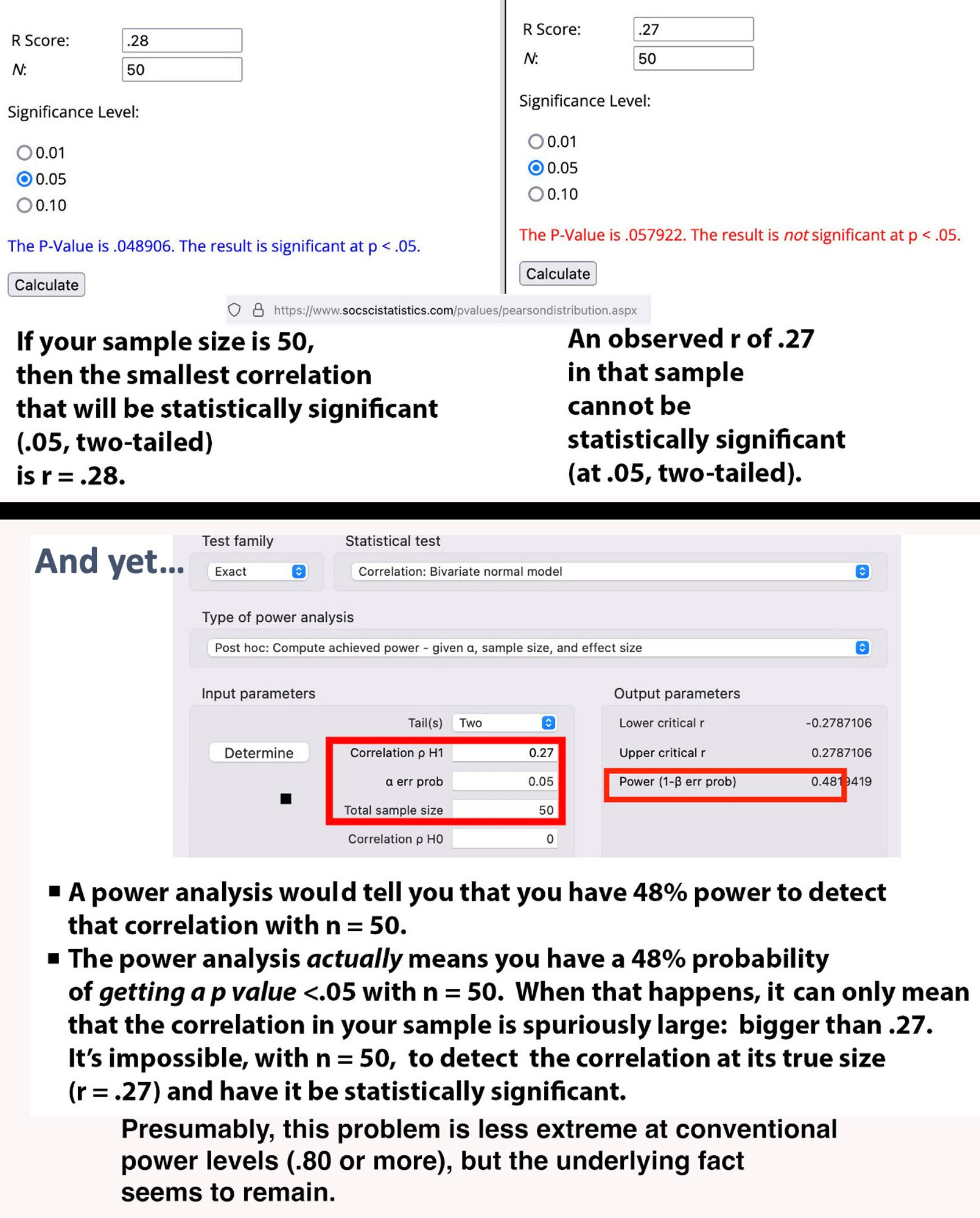
A statistical significance test of a parameter whose value is right on the line of significance will have power = .50. Because parameters all have sampling distributions when calculated in samples, you're right that you'd be half as likely to find a statistic below the parameter's value as above it.
I guess not if you take confidence interval lower bounds seriously?
DE
David Epstein
@davidnotdave.bsky.social
Literature major, then neuroscience Ph.D., then addiction researcher. Enough-knowledge-to-endanger-myself in social sciences and statistics. He/him. Views my own.
110 followers118 following20 posts