me too! 🙂
Lastly, here’s a quote: “Time is short and it doesn’t return again. It is slipping away while I write this and while you read it, and the monosyllable of the clock is loss, loss, loss, unless you devote your heart to its opposition.” -T. Williams + a song: tinyurl.com/membliss Thanks for reading!

Listen to Set Adrift on Memory Bliss (Re-Recorded) on Spotify. Song · P.M. Dawn · 2013
Major thanks to my stellar advisors for their guidance! This paper involved a very new technique (comp modeling) / research area for me. I was allowed long stretches of time just to read papers and piece things together, which is a nice self-reminder to try to practice slow science. 18/
That is, information repeated hourly and then not again will likely only be important for the next few hours-days. But information repeated monthly could be important for months-years. This arrangement allows for optimizing storage according to temporal regularity. 17/
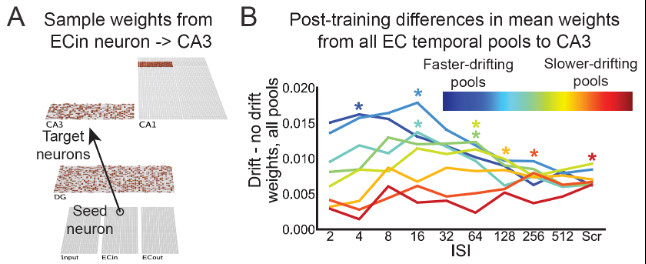
(See the paper for many more model dissections!) So, why does this happen? Is it just a quirk of the brain? We argue that, given computational constraints, it may be optimal to strengthen memories according to their temporal regularity. … 16/
We found temporal abstraction by training the model w/ a range of ISIs (increasing powers of 2). Increasing ISIs resulted in greater strengthening in slower-drifting pools from EC-CA3. This helps retain memory access for longer according to the temporal regularity of training. 15/
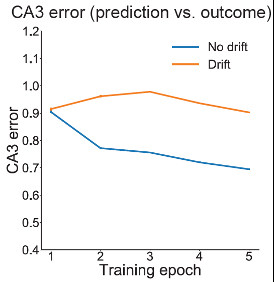
Drift in this scenario (left) ⬆️ memory most at long RIs (middle), including w/ fully scrambled temporal contexts (final data point). Thus, drift ⬆️ memory even w/o contextual support. As predicted, drift ⬆️ error between model predictions and outcomes, as shown in hippocampal area CA3 (right). 14/
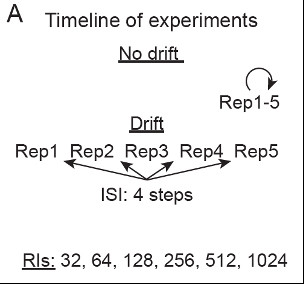
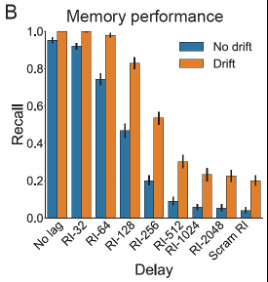
Decontextualization can be shown by testing one model with drift between epochs vs. another without drift. (The latter is biologically impossible, but also how most neural networks learn!) 13/
The relationship between ISI:RI is therefore non-monotonic, as exemplified by these findings (left) whereby the optimum ISI increases with increasing RI. Our model (right) captured these properties beautifully. (See the paper for other spacing effect simulations!) 12/
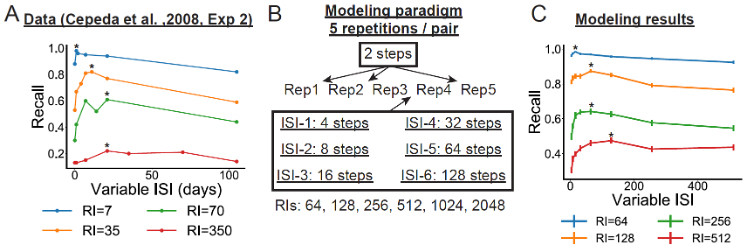
Then we simulated various spacing effect findings. One peculiarity of the spacing effect is that more spacing is not ALWAYS better: with short retention intervals (RIs) before tests, often short interstimulus intervals (ISIs) are better. 11/