Sure! Thanks for checking beforehand, appreciate it :)
The objective function itself is something I tried to steer away from, which is why it is identical in my models, to fix it so as to abstract it away from the conclusions I agree the “intuition” has limits, even a baby moves with purpose eventually, but learning continues!
We close up by discussing some of our views on learning and plasticity in cortical structures in the brain. Happy to chat more with anyone thinking about these questions!
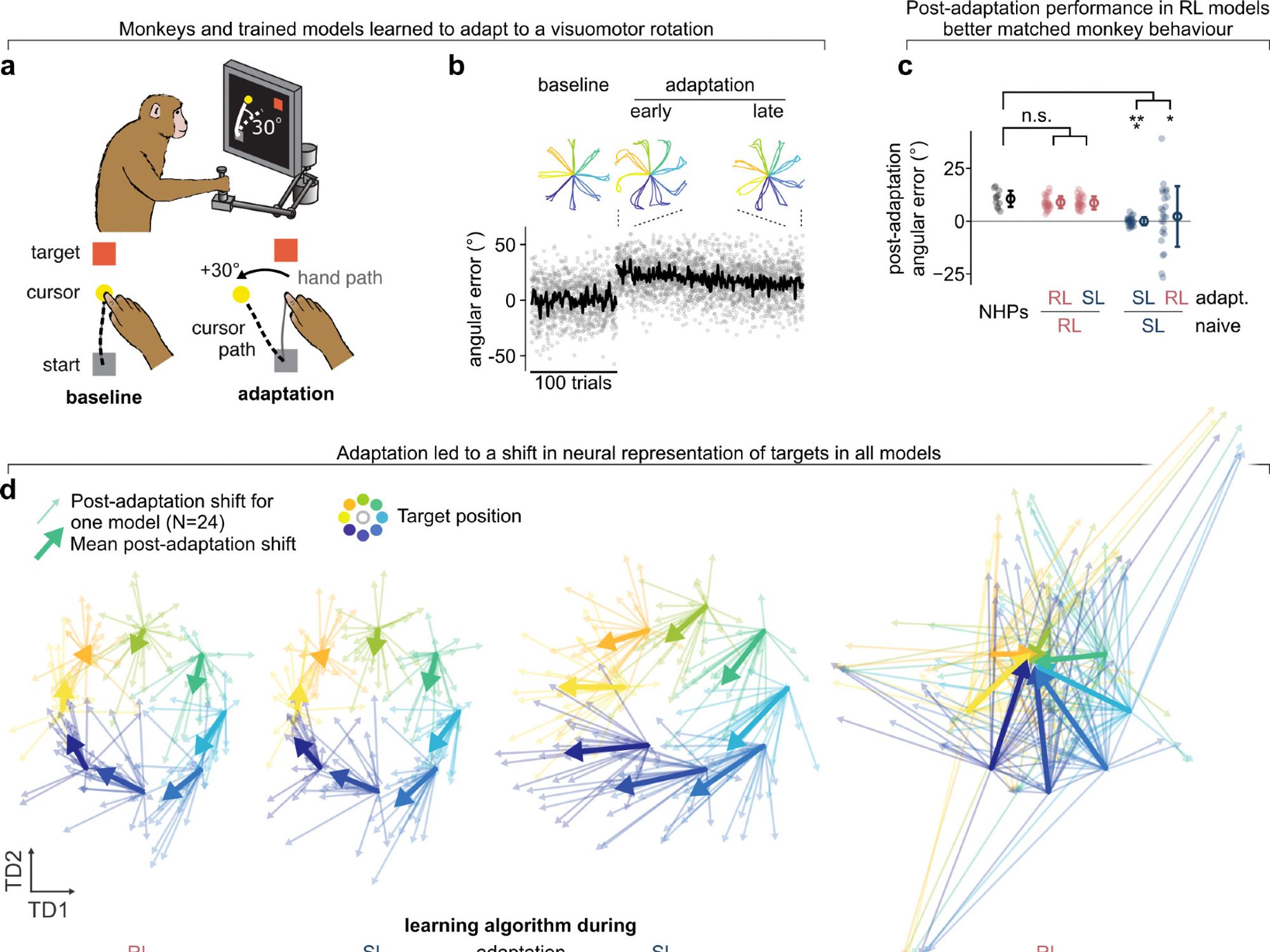
Finally, we show that the neural representations produced by RL have stabilization properties when fine-tuning to new environmental dynamics. Unlike supervised learning, this leads to representational reorganization that mirrors cortical plasticity in monkeys.
We tested these results in a biomechanically simplified setting & found that this completely breaks down, underlining that these different neural "solutions" actually depend on a more complex output-state maps. This sheds a new light on the idea of "universal solutions" for neural networks.
We found that models trained with RL aligned much better to monkey data in an matched reaching task. This was true with a crude geometrical metric (CCA) and dynamics metric (DSA) over tasks/datasets, and monkeys.
A long-standing question in psych and neuro is what serves as a dominant "teaching signal" over which to optimize when learning new skills. Instead of approaching this behaviourally, we compared monkey neural recordings to modelling predictions under the same objective function using MotorNet.
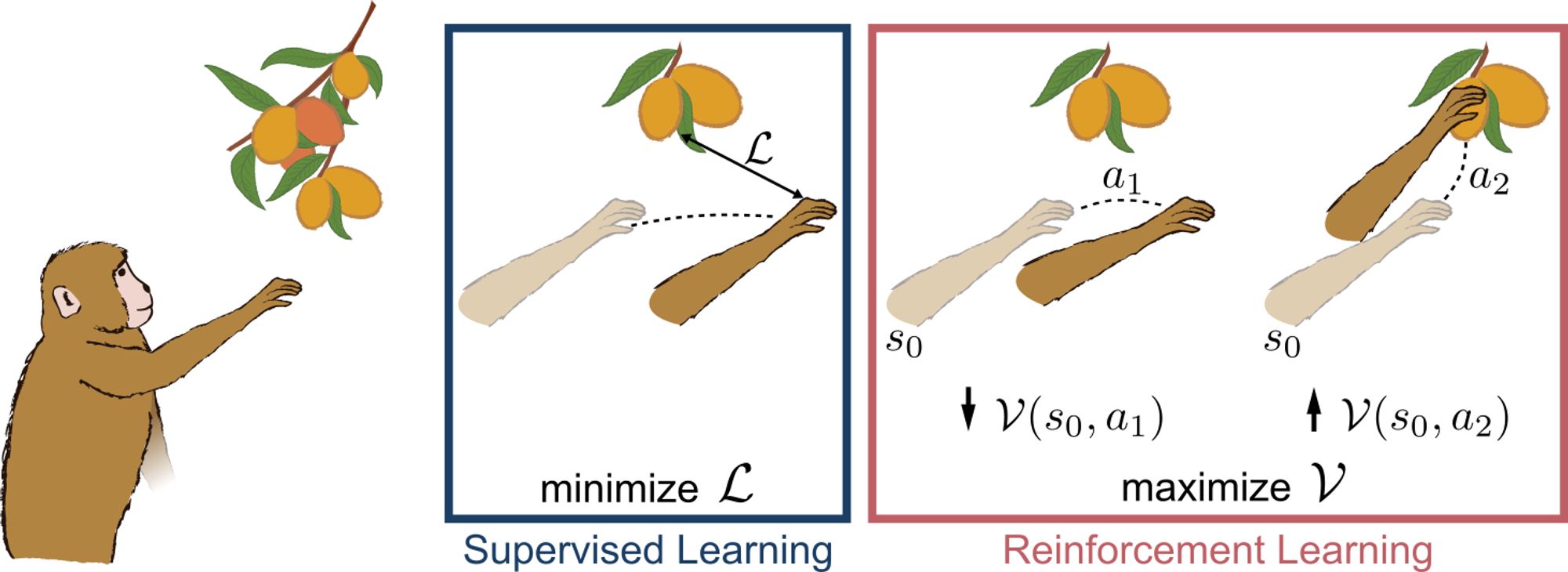
Inspired by similar lines of thinking (different flavors of RL algorithm converge to same optimal policy) we want to watch the networks learn and see how closely that matches the learning process observed in the brain. Ie www.nature.com/articles/s41...
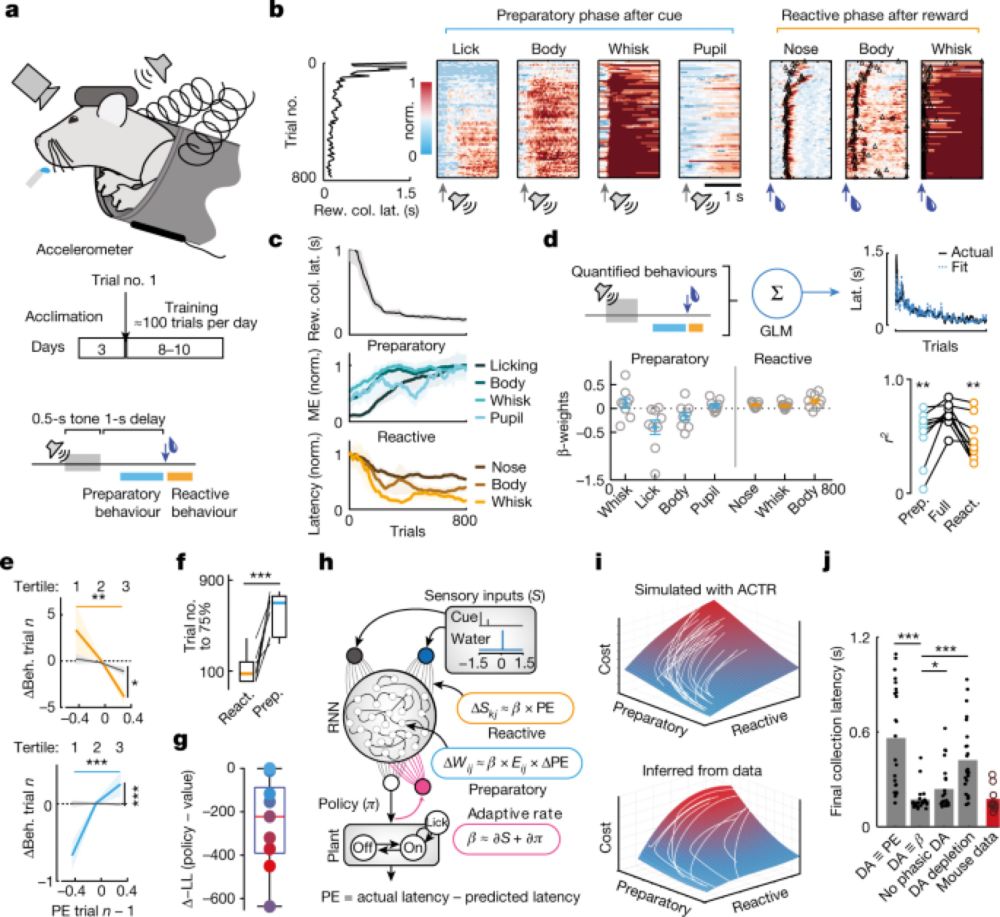
Analysis of data collected from mice learning a trace conditioning paradigm shows that phasic dopamine activity in the brain can regulate direct learning of behavioural policies, and dopamine sets&nbs...
Editor gatekeeping was ongoing beforehand though, in any journal. I don’t see the new eLife system tuning it up, if anything it’s more obvious because it is the sole remaining gatekeeping mechanism.
Overall we hope the changes go in the right direction to further enable smooth research efforts. Please do leave feedback, suggestions, and reports if you find bugs or would like to see some features implemented. Happy new year!