
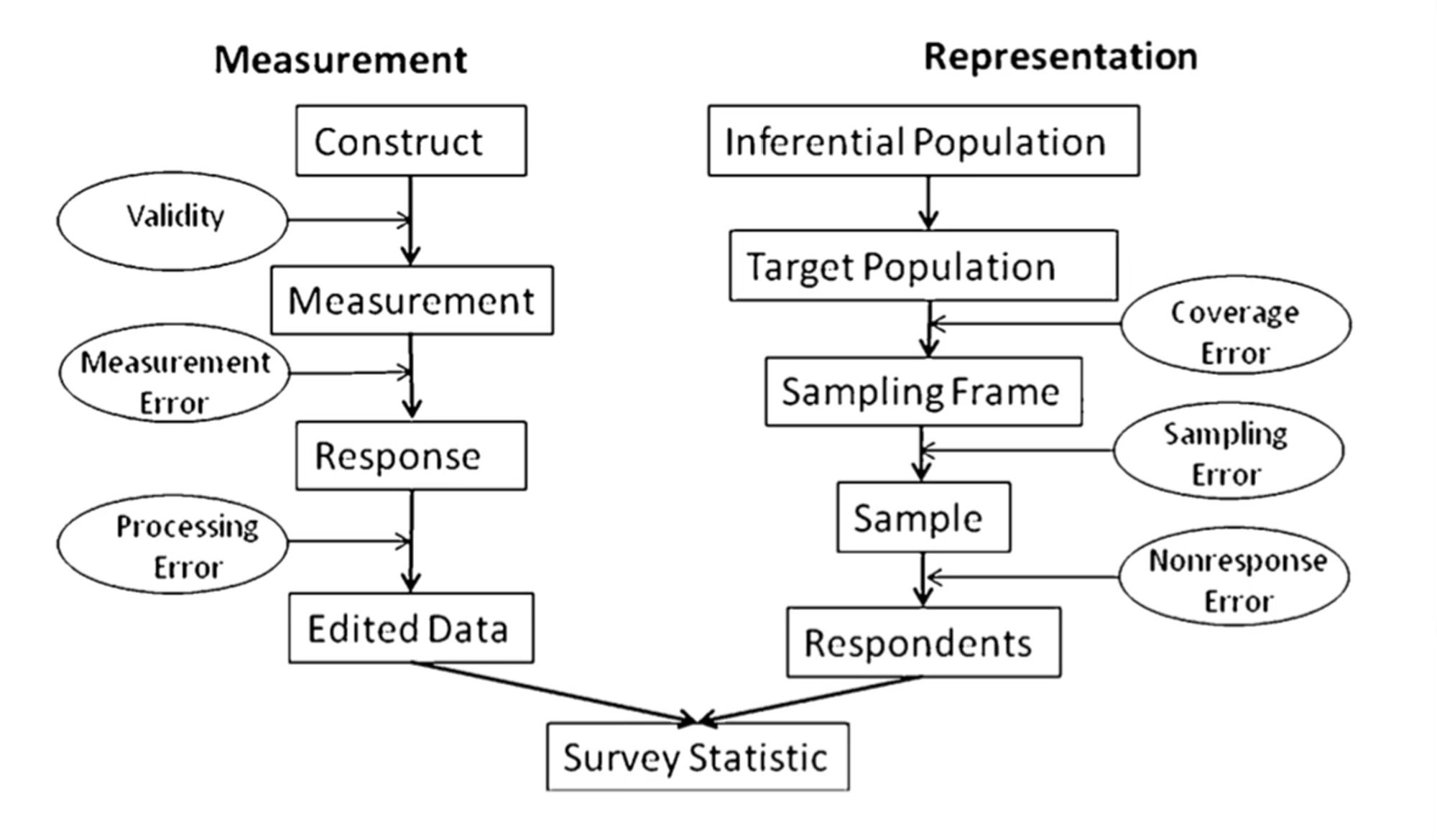
Keep thinking about this. Why don't we have a similar "total experiment error" framework as a default setting for inference from social science experiments? Oftentimes we pretend all we need to account for is sampling error even though we know our measurements, treatments, etc. are full of error.
I have a paper that was originally written to argue TSE was transportable to other empirical methods. Reviewed made me downplay TSE a bit but it's still there: www.tandfonline.com/doi/full/10....

This paper discusses the assessment of quality of quantitative communication research in light of the so-called ‘replicability crisis’ that has affected neighboring disciplines. For social scientif...
I both want to write something about this and feel like there's gotta be much more qualified people for the job. Then again, where are they and why haven't they already written about it?
The revealing one for this in my area was realizing that seemingly ~nobody had ever thought about error in Decennial Census aggregate data until the Bureau introduced differential privacy, at which point everyone freaked out.
One of the odd things about Deborah Mayo's career is that /Error and the Growth of Experimental Knowledge/ is very good on this, and then the later stuff/uptake is much more narrowly focused on p-values
If you think about the right side, that corresponds VERY roughly to validity. One of the things I take away from Kane (1992) is that validity is an argument, NOT a term of art. I agree that we can think about global sources of error usefully, as long as we know it's incomplete.
This sounds to me like a Safety II-ish situation. I hate gaslighting, so not accounting for known sources of error would bother me a lot. And yet, people might find the thought of dealing with *all* the errors overwhelming. www.england.nhs.uk/signuptosafe...
when I do bootstrap sampling, after sampling data points I like to also sample the values according to an error distribution if it’s known. seems like a simple way to incorporate error but don’t think I’ve seen literature on it!
It is **such** a helpful way to approach inference, but I have not seen anything similar in other fields.
See here, on page 230 czasopisma.uwm.edu.pl/index.php/pp...