Just told my partner yesterday that even if I had another two weeks between Saturday and Sunday I would still be late on a few deadlines come Monday
אתה יכול להרחיב?
Importantly - we'd love to hear your comments, feedback, and GitHub issues! In particular if there’s additional prior work on this topic that we should note.
But CV is used not just for evaluation but also for hyperparameter tuning, and distributional bias impacts HPs that affect regression to the mean. For example, we show that it biases for weaker model regularization, which might affect generalization and downstream deployment.

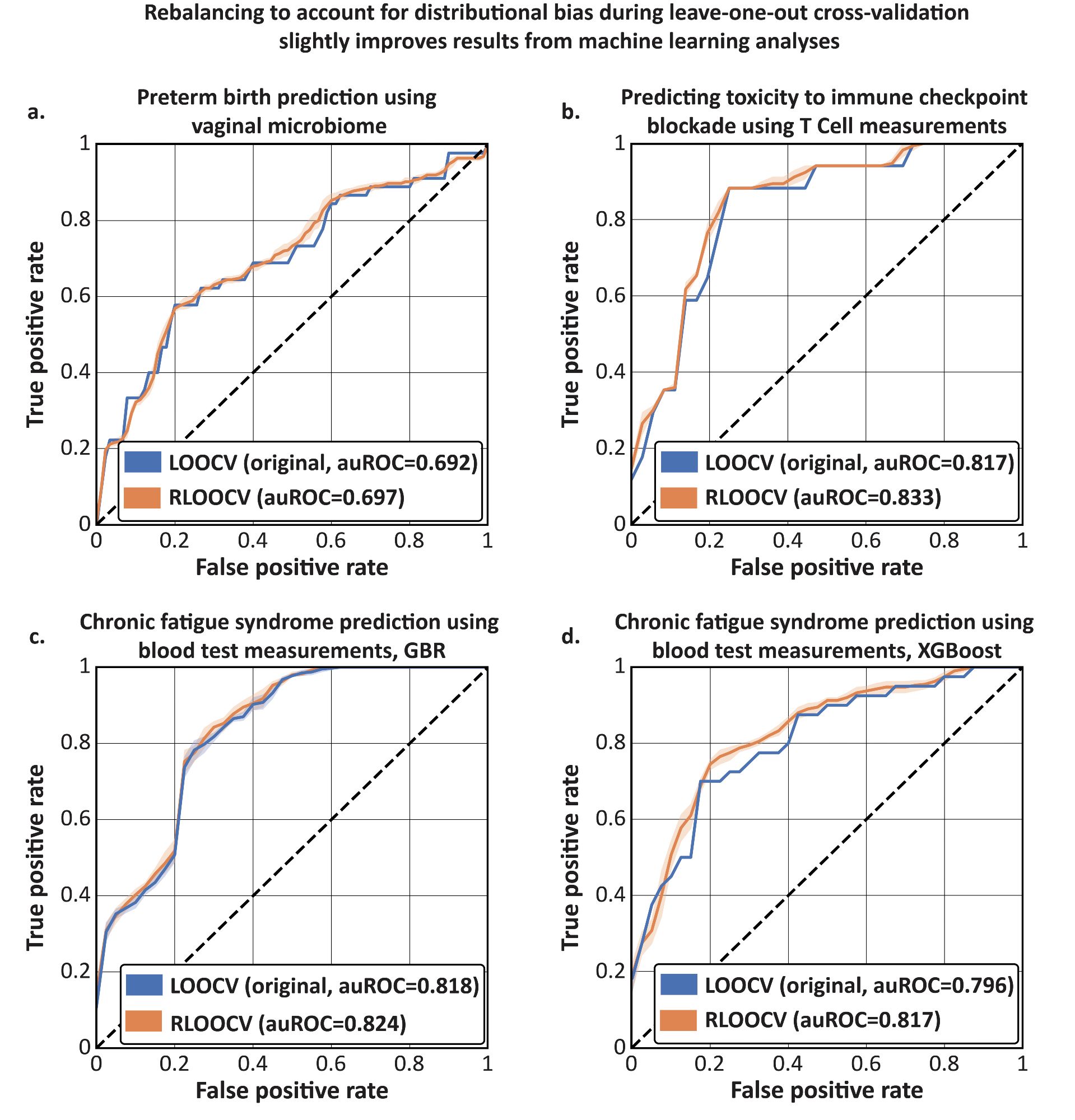
With RebalancedCV we could see the "real-life" impact of distributional bias. We reproduced 3 recently published analyses that used LOOCV, and showed that it under-evaluated performance in all of them. While the effect isn't major, it is consistent.
With this in mind, we developed RebalancedCV, an sklearn-compatible package which drops the minimal amount of samples from the training set to maintain the same class balance in the training sets of all folds, thus resolving distributional bias. github.com/korem-lab/Re...

Contribute to korem-lab/RebalancedCV development by creating an account on GitHub.
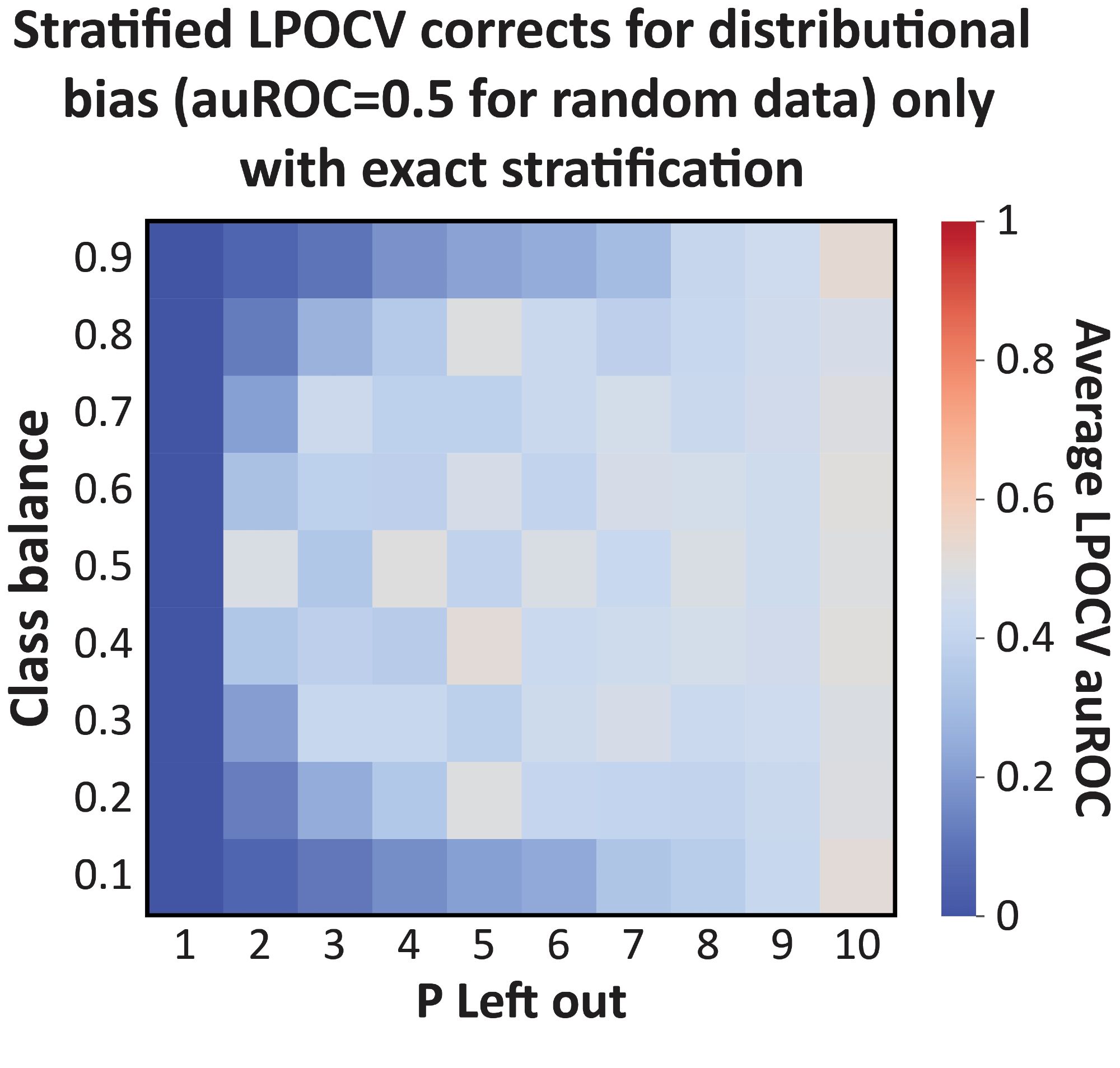
As the issue is caused by a shift in the class balance of the training set, distributional bias can be addressed with stratified CV - but only if your dataset allows it to happen precisely. The less exact the stratification - the more bias you have (in this plot, closer to 0).
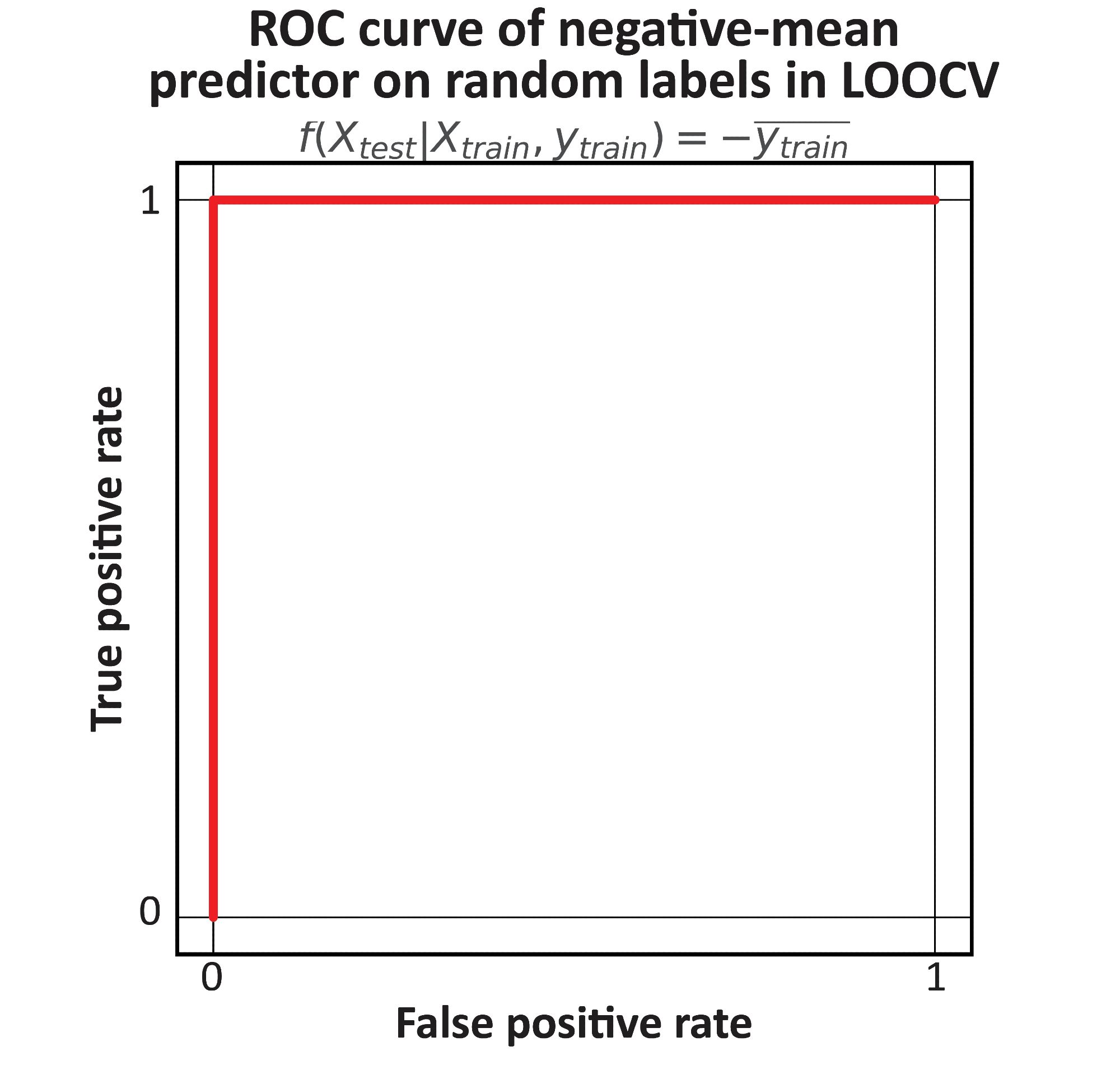
Does this mean that past work with LOOCV is overinflated? Not quite. Most machine learning algorithms regress to the mean - not to its negative - and so they are actually _under_evaluated. That's the negative bias we started with!
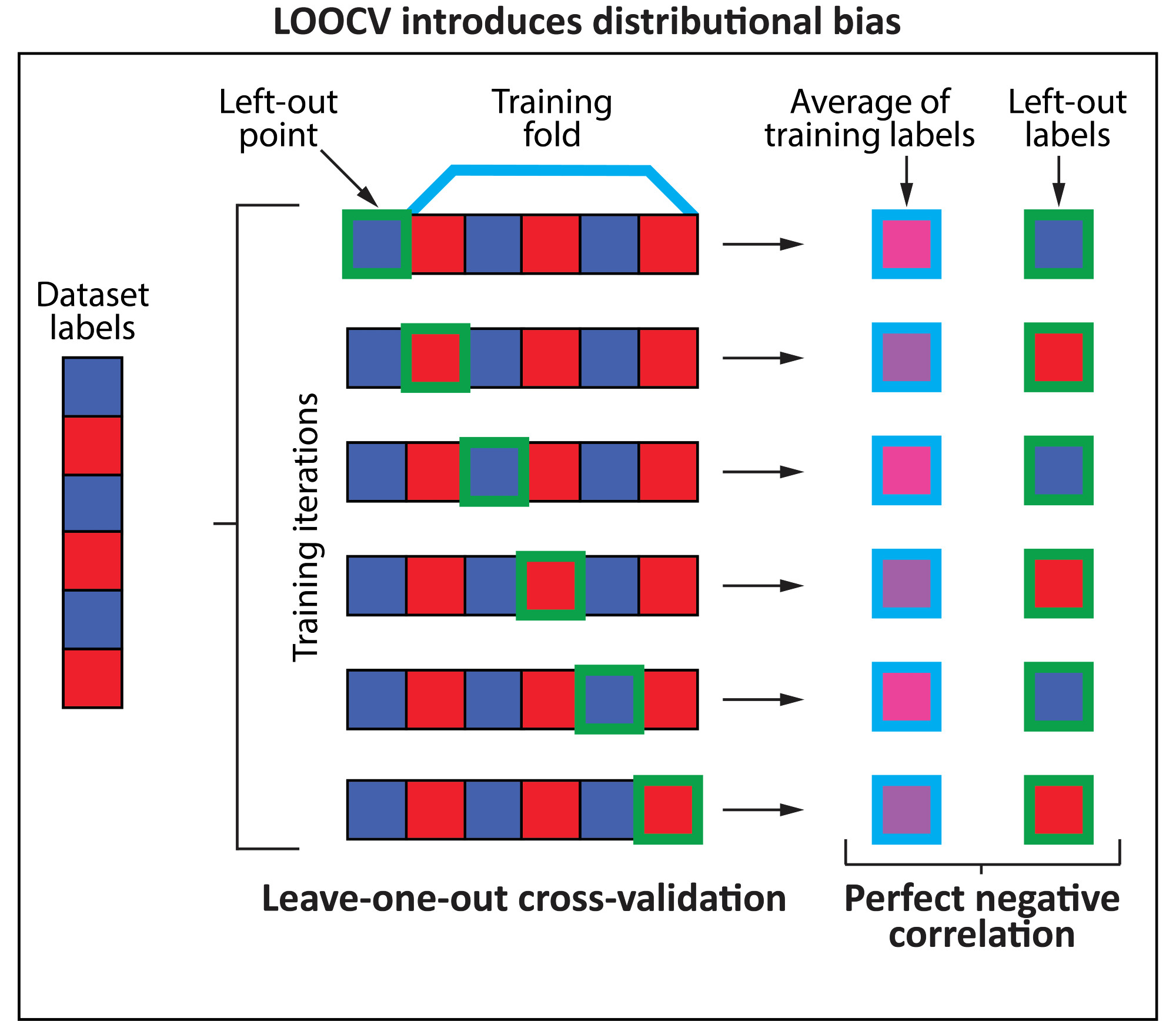
Distributional bias is a severe information leakage - so severe that we designed a dummy model that can achieve perfect auROC/auPR in ANY binary classification task evaluated via LOOCV (even without features). How? it just outputs the negative mean of the training set labels!
The issue is that every time one holds out a sample as a test set in LOOCV, the mean label average of the training set shifts slightly, creating a perfect negative correlation across the folds between that mean and the test labels. We call this phenomenon distributional bias: